2024年04月02日
要約
2024年4月27日 17:25 ~ 23:00 ukfes が大岡山劇場にて開催されます(詳しくは以下URL)
「うなばん!」で以下3曲やる予定です
スピッツの「ハネモノ」
ASIAN KUNG-FU GENERATION の「転がる岩、君に朝が降る」
新曲(オリジナル)
来てくれ!!!!!!!!!!!!!!!!!
バンド結成しました
めちゃくちゃ勧誘されたので、ギターを買ってバンドを組むことにしました。メンバーは以下です。
うなすけ(僕) ギター、ボーカル
りょぺこさん ギター
あそなすさん ベース
ukさん ドラム
おしょうゆさん キーボード
バンド名は「うなばん!」です。ホントに?いい名前が思い浮かんだら変わるかもしれません。
「新曲」?
初ライブでオリジナルの新曲があるの正気か?と思うんですが、あるのでしょうがないです。この新曲についてはライブが終わったあとに書こうと思っているふりかえりで色々書くつもりでいます。曲はめちゃくちゃカッコイイので気になってる人はぜひukfesに来てください!!!!!!!!!!!
2024年03月31日
IETF 119 Brisbane
IETF Meeting参加シリーズも4回目、リモート参加シリーズだと3回目になりますね。2024年3月のIETF Meeting 119はオーストラリアのブリスベンで開催されました。TZはUTC+10なので日本からリモート参加しやすかったです。
オーストラリアといえばカンガルーということで、参加者向けメーリングリストでは「カンガルーに遭遇した場合はどうすればいい?Internet Draftの共著者にならないか誘うべき?」などの会話が行われていました1
参加したセッション
前述したとおりブリスベンのTZはUTC+10なので、各種ミーティングがUTC+9の時間で生活している自分にとっては人道的な時間に開催されるのは助かりました。ただ、それはつまり日々の仕事などの日常生活とバッティングするということでもあり、どのみちフルで参加することはできませんでした。
あとやっぱりリスニングは壊滅的でした。本当にわからない。
それでは以下、常体です。
Media Over QUIC (moq)
Agenda
https://datatracker.ietf.org/meeting/119/session/moq
Readout from Hackathon
MoQの6つある(?)実装のうち、5つはversion 3(draft-ietf-moq-transport-03)に対応したとのこと。具体的にどの実装が、みたいな情報が見あたらないけど……
Subscribe and Fetch (draft-ietf-moq-transport)
SUBSCRIBE が送信されるとき、実際には何が送信されるのか、subscriptionの重複が存在する場合にオブジェクトが何度送信されるかが不定、などなどの不明瞭および不正な点がissueとして挙げられていて、それを解消するために FETCH という仕組みを提案するもの。
Fetch is a “StateFul” request, finds out about “non-available objects” in that range.
と述べられている。
そんなわけで今はここで議論が進められているのかな?
Split SUBSCRIBE into SUBSCRIBE and FETCH by ianswett · Pull Request #421 · moq-wg/moq-transport
draft-ietf-moq-transport
で、それとは別にdraft-ietf-moq-transport-03でのupdateの報告。いくつかのメッセージがmerge、追加されたり、曖昧な部分の明確化が行われた。今後の課題としては前述のSubscribeの問題の他に、Transmission、Object Model Details、Handshakeがあるとのこと。
draft-mzanaty-moq-loc-03
CMAFに代わるメディアフォーマットであるLOC(Low Overhead Container)を標準化するもの。WebCodecベースで、CMAFよりもオーバーヘッドが小さい。
03でなんとMLSの仕組みを利用したE2EEへの参照 が追加されたり、Audio/Video共に様々なパラメータや拡張が追加された。
“Separate packaging container format from MOQ Streaming Format?” に関して意見が分かれていたようだ。
draft-wilaw-moq-catalogformat
catalogのupdateにJSON Patchを使うようになったり、トラック名が相対的に、名前空間を継承するようになったりする変更がmergeされている。今openなものとしてIANAにcatalog fieldsを登録したり、trackに共通するfiledsを持てるroot objectを追加したりなどがある。
Call for Adoptionということは近いうちにWG draftになるのかな。
WARP draft Update (draft-law-moq-warpstreamingformat)
https://datatracker.ietf.org/doc/draft-law-moq-warpstreamingformat/
話されてた?議事録にも特に詳細がないので新しいtopicはなかったのかも。
Transport Issues (draft-ietf-moq-transport)
そしてMoQ Transportのissueについての議論。このへんちょっと議題の認識がごっちゃになってるかもしれない。GroupおよびTrackが終了するのはいつか、優先順位はどうするか、みたいな議論がもりあがっていた。次のIETF Meetingまでにinterim meetingをやろうという意見が投票多数。
Lessons from implementation
https://datatracker.ietf.org/meeting/119/materials/slides-119-moq-simulcast-video-delivery-learnings-01
サイマルキャスト、優先度、輻輳制御について。回線状況が不安定な場合の挙動について色々課題が出てきていて、FECについての研究やmoq WG以外のWGと連携することも提案されている?(BBRv3の改善とか)。
Bandwidth measurement in MOQ
https://datatracker.ietf.org/meeting/119/materials/slides-119-moq-bandwidth-measurement-for-quic-00 (pptxです)
様々な映像ソースを使って帯域測定をした結果とのこと。Özyeğin University(なんて読むんだ、トルコのオジェギン大学?)の方からの発表。
帯域幅測定はクライアント側で行うことが可能。共有だけで特に議論とかはなかった……のかな?(録画を見てるけどたぶんない)
MoQ Secure Objects
MoQでE2EEをやるための仕組みの提案。CMAFのほうにはCommon Encryption(cenc)というのがあるんだけど、それの代替というわけではなく、Low overhead containerのほうでcenc的なことを実現するためのもの(そのまま使うことができないので)。
新しい暗号を導入するのではなく既存のHKDFとAEADを使う。MLSやLOCとのeasy integraionを目指している。"Why focus on low bandwidth" に “Lyria is a 3kbps audio codec. Newer ML codecs are use even less bandwidth.”(原文ママ) とあって、Lyra、あったな~~~となった。
Lyra V2 - a better, faster, and more versatile speech codec | Google Open Source Blog
質問でCGM-SSTなるものに言及があったけど、これだろうか。
https://datatracker.ietf.org/doc/draft-mattsson-cfrg-aes-gcm-sst/
そして内容がよく聞きとれなかったけど、議事録には “Maybe use GCM-SST? (Sure)” とあるのでこれを使うということ?
WebTransport (webtrans)
もともとQUICに興味を持ち始めたきっかけがWebTransportだったのに、このWGを追うのを忘れていたな~、と。
Agenda
W3C WebTransport Update
WebTransportに関わる標準化はIETFとW3Cの両方で進められていて、W3CのほうはWeb browser APIとかを担当している(という理解をしている)。
W3CのほうでのWebTransportは、6月にAPIを安定させ、8月には複数の実装が存在している状態を予定しているっぽい?
めちゃくちゃ長い名前のオプションが追加されてる。
現時点でSafariのみが未実装。 https://caniuse.com/mdn-api_webtransport
draft-ietf-webtrans-http2
118から 08が出て、CLOSE_WEBTRANSPORT_SESSIONとDRAIN_WEBTRANSPORT_SESSIONがHTTP/3のほうから追加されたり、いくかのcapsuleがrenameされて短くなった。
draft-ietf-webtrans-http3
https://datatracker.ietf.org/doc/draft-ietf-webtrans-http3/
https://datatracker.ietf.org/doc/draft-ietf-quic-reliable-stream-reset/ への参照が追加されたり。Flow controlについてどうするかの議論がさかんだったかな?ただinterimは予定されなかった。
QUIC (quic)
masque wgも追いかけたほうがいいのかなという気持ちもありつつ、もういっぱいいっぱいなので……
Agenda
FECについては発表だけ、Accurate ECNは時間切れになりました。
QLOG (draft-ietf-quic-qlog-h3-events)
Dune: Part Two観てないんですけど、観たほうがいいですかね。
118以降、QPACK関連のイベントが削除されたり、イベント名がちょっと変わったり、Multipathのサポートが入ったりした。今年末にはWGLCしたい、という雰囲気?
もっとMoQ wgと連携していこう(あとでメールしてほしい)、という話が出た。
Multipath QUIC (draft-ietf-quic-multipath)
Path IDをどうするか、interopの結果がどうだったかなど。Path IDについては292で提案されているExplicitなものと現在の06とのPros/Consがそれぞれ挙げられている。MPTCPというのがあるのか。
retire CID on all pathsについては賛否が分かれたのかな?
Ack Frequency (draft-ietf-quic-ack-frequency)
いくつかの文章と変更と明確化、特に対応せずcloseしたものなど、前回からの変更についての報告。
2度目のWGLCを119が終わったあとにしたい。
QUIC security considerations
https://datatracker.ietf.org/meeting/119/materials/slides-119-quic-honeybadger-and-his-friend-the-mongoose-00
QUICに対するリソース枯渇攻撃についての共有。HTTP/2 Rapid Reset Attachに似ている?QUICサーバー側のactiveconnection idlimitを越えてNEW CONNECTION_IDをはちゃめちゃに送りつけるという攻撃、なのだろうか。
https://seemann.io/posts/2024-03-19-exploiting-quics-connection-id-management/
この記事に詳しく記載されている。
QUIC on Streams (draft-kazuho-quic-quic-on-streams)
新キャラ。TCPとUDPでの二面待ちをしたり、新しい概念が導入されたときにTCPとUDPの両方に対応する必要があったりするので、TCP上でQUICを話せるようにしようというもの。QUIC on Streamsはあくまでもfallbackであって、TCPで発生し、QUICが解決したHOLBの問題はこっちでも頑張って解消しようとはしていない。……で、あってるのかなあ。
スケジュールだと5分という話だったけどまあ5分で終わるはずがなく。どっちかというとQUICを推し進めていくほうがいいのでは?という反対意見のほうが多かった……のか?
BDP frame (draft-kuhn-quic-bdpframe-extension)
BDPは"Bandwidth Delay Product"の略。輻輳制御に関するパラメータを両者間でやりとりして、Careful Resumeを実現するもの。もしかしたらCCWGでやることになるかも?QUIC WGがこれを進めていくかについては賛否が分かれた。
Transport Layer Security (tls)
Agenda
8446bis/8447bis
Chairのところで止まっていて、報告されているエラッタを処理しなければいけない。なんかエラッタを草案のコメントとして使ってる人がいて?全部closeになるかも、という話をしていたかも。
ECH Update (draft-ietf-tls-esni)
Encryptred Client Helloになってからも、Encrypted Server Name Indication時代の名残で draft-ietf-tls-esni なの、混乱しますよね。
これも今月いっぱいはIn WGLCという報告。
Registry Update
https://datatracker.ietf.org/meeting/119/materials/slides-119-tls-tls-registry-updates-00
IANAの人からの報告。rejectされたrequestはなし。Extensionがいくつか増える(スライドにあるのは4つ)。ALPNも作業中のものがCoAPの表記について?
TLS Hybrid Key Exchange (draft-ietf-tls-hybrid-design)
https://datatracker.ietf.org/doc/draft-ietf-tls-hybrid-design/
大幅には変わっていないが、Hybrid Groupsの数が2つに削減された( X25519Kyber768Draft00 と SecP256r1Kyber768Draft00 )。FIPSの認証と、共有鍵と合体させる(?)方法についてが残っている問題。
“Chrome announced today they are going to release an experimental version.” って言ってて、どれだよ……となっている。
一番「それっぽい」のはDev channel 2023-03-16の 124.0.6356.6のリリース(上の2つめのリンク)で、"Enable PostQuantumKyber by default on desktop" っていうcommitが入ってる。でもこれAndroid……?3つめのリンクはそのcommitに関連付けられているChromiumのissue trackerにおけるチケット。diffの中身も「っぽい」んだよな。Firefoxのほうは “Firefox is shipping in nightly currently.” とのことで。https://bugzilla.mozilla.org/show_bug.cgi?id=1871629 から辿れそうだけど具体的なcommitまではわからなかった。
TLS Obsolete Key Exchange (draft-ietf-tls-deprecate-obsolete-kex)
これ、 In WG Last CallになってるけどExpiredっていうStatusはアリなのか?(chairの作業で止まってる、とスライドにはある)
FFDHEについて、TLS 1.2では Discouragedに、TLS 1.3ではNot recommended(議事録ではOKとしか書いてないけど、でもrecommendedではないでしょう)となることになりそう。
Static DH Client Certificatesについても非推奨とされる流れ?
TLS Formal Analysis
https://datatracker.ietf.org/meeting/119/materials/slides-119-tls-formal-analysis-triage-panel-00
個人的には今回のTLS WGのミーティングで最も盛り上がった議題だと思う。8773bisがlast callするにあたり、いくつかのWGのメンバーから「その変更に対するformal analysis(形式的分析)が行なわれていない」という意見があったらしい。
つまりTriage panelを置き、TLS 1.3の標準に変更が入る際にはtriage panelに連絡し、そこで正式にformal analysisを行うかどうか判断するようにしようという提案っぽい。
“Not just Tamarin” というのは標準化界隈でよく使われる(らしい)セキュリテイプロトコルの検証ツールとのこと。
https://tamarin-prover.com/
で、not justなのでTamarinに限らず様々なツール、手法で検証をしようじゃないか、という。
賛成の声が多い感じ。学生を巻き込みたいという意見もあった。
Super Jumbo Record Limit (draft-mattsson-tls-super-jumbo-record-limit)
SUPER JUMBO
TLSのrecord size limitを RFC 8449にて定められている2^14 バイトから 2^16 バイトまで拡張できるようにするもの。データセンターで有益という意見。性能指標についてどうなるのか、という疑問点が挙げられ、今後識者と協力してやっていく、ということに。
mTLS FLag (draft-jhoyla-req-mtls-flag)
クローラー、Botが「自分は真正なクライアントですよ、ほら証明書がありますよ」をサーバーに知らせるためにmTLS readlyであることを送る仕組み。
実はもうここ https://tls-flags.research.cloudflare.com/ で動いている。CとGoでの実装もあるみたいだけど資料には記載がない。でもGoは多分これ https://github.com/cloudflare/go/pull/151
“I would like to see enthusiasm.” ということは、もっと協力なニーズがないと厳しいのか?
Extended Key Update (draft-tschofenig-tls-extended-key-update)
長生きなTLS connectionにおいての鍵更新をなんとかしたいという話。TLS 1.2での再ネゴシエーションが脆弱であるということでTLS 1.3では削除されている仕組み。(ラムダノートさんの「プロフェッショナルTLS&PKI改題第2版」 では「8.1 安全でない再ネゴシエーション」として記載があります)
これが、通信インフラやIoT機器などのコネクションが長生きする場面において通信内容をよりセキュアにするために有用であるという提案。仕組みではpost-quantumでも使われるKEMを使う?RFC 9180 を参照するとのこと。
設計が複雑になるのでは?という議論になった感じだろうか。
ML-KEM for TLS 1.3 (draft-connolly-tls-mlkem-key-agreement)
耐量子での鍵確立をやるってことですね。Named Groupに mlkem768(0x0768) と mlkem1024(0x1024) を足す。ていうか、耐量子暗号って7年前には既に提案されていたんですね(早すぎるのでは?というFAQ)。
hybridでやるべきでは?という意見、RFCではなくコードポイントの定義だけでいいという意見、強く支持するという意見、これはひどいアイデアだという意見などなどなどがあり、一体どうなっちゃうの~~?
まとめ
むずかしいですね。mls、httpbis、httpapi、ccwgについてもまとめたかったんですが、ギブです。
2024年02月25日
楽々静的HTTPサーバーことpocke/wwwとは
これらをご覧ください。ちょこちょこpull reqを投げていたらコミット権をもらえた1
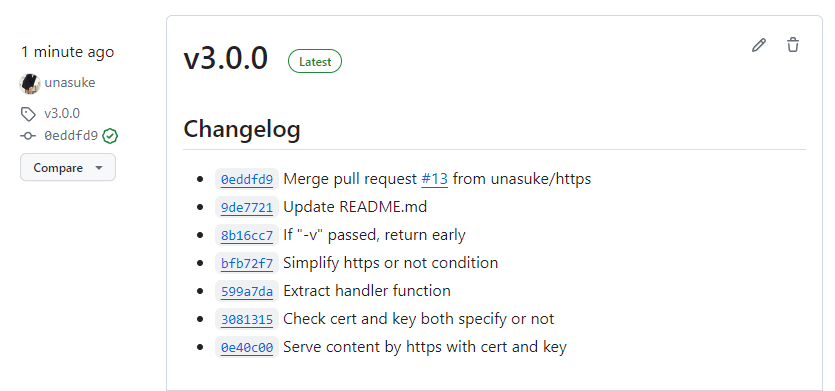
タイトルでは「v3.0.0をリリースしました」と言っていますが、その前段階で v2.0.3 をリリースしているので、ついでにそれにも触れていきます。
v2.0.3
この変更で行なったのは以下の2つです。
Windows版buildの配布を追加
deprecatedとなったioutil.ReadFile の削除
Windows版buildの配布を追加
僕はたまにWindows環境でwwwを使いたいことがあったのですが、リポジトリのreleaseにはLinuxとDarwin(macos)向けのビルド済みバイナリしか存在しませんでした。GoなのでWindows版バイナリを用意するのは簡単ですが、用意されているほうがありがたいですよね。
wwwはリリース作業にGoReleaser を使用しているので、.goreleaser.yaml を用意してWindowsをtargetにしてやるだけで対応完了です。
ちなみにpull requestは1年以上放置していました。よくない。
deprecatedとなったioutil.ReadFile の削除
エディタでmain.goを開いたときに気付いたのですが、内部で使用しているioutil.ReadFileがdeprecaredとなり警告が発生していました。
これは単純に os.ReadFile に置き換えるだけで対応完了です。
v2.1.0
HTTPSへの対応を追加しました。
HTTPS対応
これについては、himanoaさんのこの発言を見たのが対応のきっかけです。
そんなわけで、 --cert と --key に証明書のpathをそれぞれ指定することでhttpsによるリクエストを送ることができるようになりました。このoptionは、両方を指定しないとエラーになるようにしています。
まとめ
CHANGELOG.mdとかあったほうがいいのかな、という気もしてきましたが……そこまででもないかな?とにかく、pocke/www は便利なのでよろしくお願いします。
2024年01月28日
予習
「RubyKaigi 2024に向けて泡盛を予習しておきたい」ということになり、今月頭に沖縄に行ってきました。
写真
以下、様子です。
知見
高速道路に合流がなく料金所を通過すると即本線なのが新鮮
ステーキが本当に美味しい
自販機のラインナップが新鮮
美ら海水族館のリン子どんはもっと知られてほしい
いわゆるスパムおにぎりはツナのほうがいいかも(まだ食べれていない)
泡盛コーヒーは知能が高い飲み物であり、ファミマは知能が高いコンビニ
海が綺麗
国際通りのドラッグストアには酒豪伝説があるので安心
2023年12月24日
3行で
C103 2日目(12/31) 東ヘ17a 「キリンセル」にて「TLS 1.3のRFCを読んでいく本」を¥3,500で頒布します。
内容はTLS 1.3についてのことで、表紙と挿絵をナナメさんにお願いしました。
物理の本のみ頒布します。電子版については後述しますが、現時点では存在しません。
本について
コミックマーケット103 2日目(12/31) 東ヘ17a 「キリンセル」ブースにおいて、「TLS 1.3のRFCを読んでいく本」を頒布します。この本は、Rubyアソシエーション開発助成2022 において、aiortc/aioquic をRubyに移植する際の経験をもとに書くことにしたものです。
aioquicには、TLSの実装が含まれています。そのTLSのPython実装をRubyに移植する際になかなかうまくいかず、RFCや実装とにらめっこをするなどの苦労をしたので、TLSのRFCを日本語で解説してくれる資料がないだろうかと思い、書くことにしました。
もちろん既に日本語訳を公開されていらっしゃる方もおられますが1
とはいえあまりに文書量が多く、わかりやすくまとめなおすというのは時間的に無理で、ほとんど日本語訳の形になってしました。それでもRFCには記載のない参考資料へのリンクを追加したり、言い回しをやさしくしたり語句の簡単な解説を足したりと、単なる翻訳ではないような本になるようにしたつもりではあります。
この本については、いずれインターネット上で誰でも読めるような形式で公開するつもりです。その際はMITライセンスやCCライセンスなどの、何らかの自由に利用可能なライセンスを適用します。なので、本当に今すぐ読みたい、何らかの理由でお金を払って読みたいという方でない限り、当日お越しいただく必要はないかもしれません。
そうなってしまうと結局RFC 8446を日本語にしただけじゃないか、ということになるので、ナナメさん にお願いして表紙絵とイラスト数点をお願いしました。これは後々公開予定の文書には含まれず、物理本を購入していただいた方限定のお楽しみコンテンツとなる予定です。当日お買いあげいただいた方には、表紙絵のみを印刷したものもおまけとしてお渡しします。
頒布数についてですが、50部を印刷しました。ただし全部を今回のコミケで頒布するつもりはなく2
で、現在「¥?,???」となっている頒布価格についてですが、まだ印刷所からの連絡がなく3
見本
見本はコミケWebカタログで確認することができます。
キリンセル | Comike Web Catalog
取り置き制度
pixivFANBOXおよびGitHub Sponsorsで支援していただいている方に対しては、連絡をいただければ取り置きをさせていただきます。当日お渡しする際には支援していることの確認となるものを提示していただくかもしれません。準備をお願いします。詳しくは各プラットフォームからの連絡をご参照ください。なお、申し訳ありませんが支援金額を頒布価格から差し引くという対応はしません。まあそんな爆裂に売れていくなんてことはないと思いますが……
最後に、再度コミケWebカタログにおけるキリンセルの詳細ページを貼っておきます。
キリンセル | Comike Web Catalog
追記 2023-12-29
頒布価格を決定しました。1部¥3,500です。お品書きも更新しています。
なお、すっかり言及を忘れていたんですが、同日東パ03bにて頒布される「桐生あんずファンブック」にて、「Rubyistワカモノ組座談会」で僕が話した内容が本になっています。こちらもよろしくお願いします。
2023年12月18日
4年目
今年は契約先が変わったのですが、新規契約先を探しているときに、「こういうのがあると非常に助かる」という声を頂いたので今年もやっていきます。
これまではこんな感じでした。
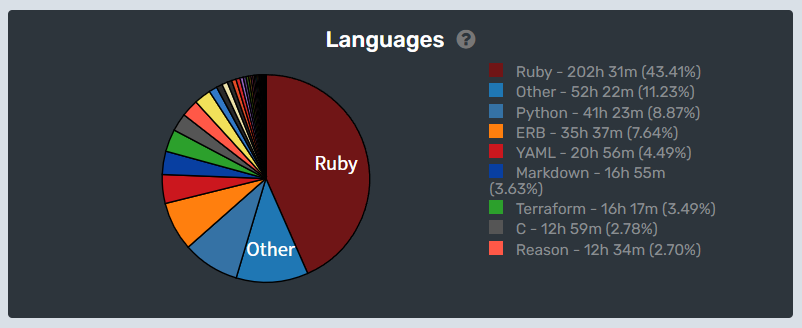
例によって冒頭の画像はwakatimeによる2023年1月1日から12月18日までのプログラミング言語使用率です。2位のOtherですが、内訳を見てみるとRBSやqlogやHamlやJsonnetでした。ReasonとなってるのはReasonでなく、Re:VIEWの .re がそう判定されているようです。(この統計には仕事で触れた言語は含まれていません)
立場(毎年同様)
フリーランスで、主にRailsやAWSを使用しているサービスの運用、開発に関わっています。いくつもの会社を見てきた訳ではなく、数社に深く関わっている都合上、視野が狭いかもしれません。
今年も仕事の成果として公表できるものはありませんでした。仕事ではありませんが、Kaigi on Rails 2023で使っていただいたconference-appはその大部分を書きました。
https://github.com/kaigionrails/conference-app
利用した技術一覧
Language
Ruby
Python
TypeScript/JavaScript
C
Framework
Rails
React
Tailwind CSS
Stimulus (new)
Middleware/Infrastructure
Docker
PostgreSQL
MySQL
AWS
Cloudflare (new)
Terraform
Kubernetes
CI
Monitoring
OS
Editor (wakatimeによる使用時間合計順)
VS Code
IntelliJ Idea系
Vim
概念的なもの
REST API
PWA (new)
QUIC/TLS
昨年からのDiffとしては、Goは触った記憶がないので削除しました。TypeScriptとJavaScriptを併記していますが、conference-appのためにStimulusを書いた都合上、TypeScriptよりもJavaScriptを書いた比率のほうが大きいと思います。
Python
昨年と比較して一番変化のある部分だと思います。これは明らかにRubyアソシエーション開発助成2022 によるものです。とにかくPythonのQUIC実装をRubyに移植するという作業をしていました。とはいってもPythonを “書いた” ではなく “読んだ” というほうが正しいですね。DjangoやFlaskでWebアプリが書けるようになったとか、そういうわけではありません。
QUIC/TLS
Python同様、イチから移植することで理解が深まったもののひとつです。昨年はここがQUICという表記でしたが、今年は明確にTLSを追加しました。実装の移植で行き詰まりRFC 8446 (TLS 1.3)を何度も読みました。
この活動がきっかけで1
日本国外での開催に現地参加するかどうかは……ちょっと悩んでいます。お金がないというのもありますが、まだまだ英語のリスニングが甘いからというのも大きな理由です。
conference-app
Kaigi on Rails 2023で皆さんに使っていただいたものです。これのおかげで、今年触った技術としてCloudflare、Stimulus、PWAを追加することができました。その後様々な方からのcontributeで、RBS(特にRailsに導入するもの)についてもちょっとわかるようになってきた、かもしれません。
来年頑張りたいこと
Ruby/QUIC/TLS
今年はGrantでの移植以降、TLS 1.3をちゃんと学び直さないといけないと思い RFC 8446: The Transport Layer Security (TLS) Protocol Version 1.3 をアタマから読み直したり、日本語にしたりしていました。
RFCは、仕様として書かれているのでそういうものかもしれませんが、特にRFC 8446は読みづらかったです。後の章で解説される概念が冒頭で出てくることが何度もあるので、そのままの順序で読むと理解に苦労します。ということで、実装する立場でもうすこしわかりやすいものがあれば、と思いそれらしいものを書いている途中です。
そもそものQUIC実装にしても、RubyKaigi Takeout 2021からもう2年も経ってるのに……という状態であり、来年こそは何らかの成果を出したいところではあります。が、どうなることでしょうね。どうしても趣味でやっていることなので取れる時間が少ないのと、コミュニティ活動もあるのでなかなか進みが遅いですが、頑張りたいです。
QUIC実装、特にaioquicの移植としてそれなりの規模のコードを書いた感想としては、RBSはやっぱりあると便利ですね。なのでOtherが2位に上がってきたのだと思います。個人でgemを書くことがあれば、積極的にRBSは書いていこうと考えています。
Kaigi on Rails
コミュニティ活動の筆頭と言えます。これは運営チームのみ見える形で「こんなことがしたい」というのを書いていて、それをやっていきたいですね。Proposalも……出せたらいいですね……
今年は初めてのin-person開催となりましたが、運営側からもそうですし、参加していただいた皆さんからも、成長する余地があることは感じられたかと思います。やっていかねば、いけませんね。
C/Rust/Zig
昨年から何もできていないですね。本当に何もできていない。無です。多分来年もあんまりここに割ける時間はないんじゃないかと思いますが、気持ちだけはあります。本当です。
Pythonと同様に書くまではいかなくても、QUICやTLSの実装の参考として読むことは多いのではないかと考えてはいます。
English
昨年、以下のようなことを書きました。
あと海外カンファレンスにProposalを出せたらいいなとか考えていますが、果たして。
こちらは、出すには出したのですがRejectになってしまいました。
一方で、RubyKaigi 2023での登壇は英語でやることにし、その登壇記も英語で書きました(DeepLにおんぶにだっこではありますが)。
RubyKaigi 2023 participation report
RubyKaigiにおいて英語で話すことの一番のメリットは、同時通訳さんとの打ち合わせのために資料を事前に提出しなくてよくなることです。その代わり、発表練習は日本語で話すとき以上にみっちりやる必要がありますが。ただ、RubyKaigiの僕の発表資料作成は、まず話すことを文章にしたうえでスライドを作っていくというスタイルなので、この点は偶然にもうまくいっています。
そしてIETFに参加するようになり、例年以上に英語に触れる、特にリスニングの時間が増えているのを感じます、が、それに英語力の上達がついていっていない……どうしたものでしょうね。
2023年11月19日
IETF 118 Prague
チェコの首都、プラハで開催されたIETF 118にリモートで参加したので、自分なりにまとめます。ただ今回、RubyWorld Conference 2023 と日程が被ってしまったため、Meetecho(ライブで会議が行われる場所、Zoomの部屋みたいなイメージ)にはあまり入れずにYouTubeのアーカイブと議事録からのまとめとなります。英語の議論についていけないのでどのみちそうなるのですが……
写真はIETFとは全く関係ない、RubyWorld Conference 2023開催地である島根県は宍道湖の写真です。
例によって正確性の保証は一切いたしません。
参加したセッション
QUIC
https://datatracker.ietf.org/group/quic/about/
Media Over QUIC (moq)
https://datatracker.ietf.org/group/moq/about/
今回もMedia Over QUICのSessionは2回ありました。議論の内容がメディア転送をやっていないとわからないようなものになってきて、いよいよ追うのに限界を感じています。
Transport Layer Security (tls)
https://datatracker.ietf.org/group/tls/about/
Messaging Layer Security (mls)
https://datatracker.ietf.org/group/mls/about/
RFC 9420: The Messaging Layer Security (MLS) Protocol が7月にRFCになったばかりですが、draft-ietf-mls-architecture-11がRFCになってくれたら、というかdraft-ietf-mls-extensions-03も結構重要な要素なので、要するにまだこれからという雰囲気を勝手に感じています。
そしてどちらかというとリソースがmimi(More Instant Messaging Interoperability)のほうに割かれてるのではないかということらしいです。しかしmimiのほうは追えておらず……
なんというか、mimiと合わせて見ていかないとだめそうです。
Congestion Control Working Group (ccwg)
https://datatracker.ietf.org/group/ccwg/about/
Building Blocks for HTTP APIs (httpapi)
https://datatracker.ietf.org/group/httpapi/about/
HTTP (httpbis)
https://datatracker.ietf.org/group/httpbis/about/
まとめ
むずかしいですね。
2023年11月03日
感謝
Kaigi on Rails 2023に参加していただいたみなさま、ありがとうございました。初のオフライン、オンラインのハイブリッド開催となりましたが、登壇者の皆様、Proposalを出してくださった皆様、協賛してくださった企業の皆様、そして一般参加者の皆様のご協力のおかげで無事に今年のKaigi on Rails 2023を終えることができました。
主役は参加者のみなさまということもあり、運営のひとりである僕からのふりかえりは手短かにしようと思います。
conference-app
もともと会場でのサイネージの役割としてのなにかを用意したいよね、という構想はあったので運営内でのみ使うWeb appを作るつもりではいたのですが、大倉さんがドーンと rails new をしたリポジトリが爆誕したのでそこに乗っかることにしました。お披露目クオリティに達したのが本当にギリギリだった1
これについては他で話すネタになりそうなこともあり、あまり詳細な言及は控えます。とはいえソースは公開されているので何をやったかは全て見れる状況ですね。ドキュメントが少なすぎるのは追々なんとかします……
https://github.com/kaigionrails/conference-app
配信
今年も昨年に引き続き配信関連の担当をしました。とはいっても今回は会場側に配信をやってくれるプランがあるので、それをお願いしました。なので当日は僕自身がなにか操作するということはありませんでした。
会期中は、配信に登壇されている方の姿や声がちゃんと乗っているかの確認のため、YouTubeを2窓して両方の発表を聞く、ということをしていました。冒頭の画像はそのために用意したディスプレイを置いていた、スタッフルームにおける僕の机の写真です。持っててよかったモバイルディスプレイ。ちなみに、手前にあるダンボール箱2つは、直前に僕が買ってきてもらうように頼んだChromebookです。
実際に配信のプロの方と組んでなにかをやる、ということは初めての経験だったのでとても勉強になりましたし、楽しかったです。
趣味 スティンガートランジション再び
今年はオフライン開催ということでそこまでしている時間がなさそうな気配があったため、配信のトランジションについては何もするつもりがありませんでした。しかしアイデアが降ってきた&やってみたら案外時間をかけずに作れたために今年も作ってしまいました。これって会場で流れたんでしょうか?もしかしたら配信限定コンテンツだったかもしれません。
VIDEO
果たしていつまで作り続けられるでしょうね。
Next
クロージングでもアナウンスがありましたが、2024年の開催は決定していますが現時点で会場がまだ決まっていません。やばいですね。
2023年10月01日
クックパッドという会社は、Rubyのコミュニティに関わっている僕にとっては特別な印象がありました。今でこそShopifyやGitHubにその座を譲っているでしょうが、世界最大級のRailsによるモノリシックなアプリケーションによるサービス提供、フルタイムRubyコミッターの登用、優秀なメンバー、技術ブログの豊富なアウトプット……いつだって「いつかこんな会社で働きたい」という会社のうちのひとつでした。
クックパッドが横浜に移転するタイミングで、多くの人が退職していくのを外から眺めていました。その勢いに、このままではいつか一緒に働きたいと思っていた人達がいなくなってしまうと思い、(以前から手が足りていないのでどうですか、という声はかけていただいていた)あそなすさんに連絡をとり、業務委託の立場で関わることになりました。
色々なことをやりました。事業に関わることはどこまで書いていいのかがわからないのであまり触れませんが、新規サービスの立ち上げ、Ruby及びRailsのアップデート、「さわるだけで開発期間が3倍になる優れモノ」とまで言われた1
事業に関わらないことでいえば、社内フェスでのDJ、チキチキ、データ指向アプリケーションデザインの読書会、Rubyに関する社内勉強会、そしてRubyKaigi。事業もそうでない部分も、本当に楽しかったです。
一方でいいニュースばかりではなく、度重なる事業の見直しやそれに伴なう人員整理が行われ、その度に寂しい思いで一緒に仕事をした方を見送ることが続きました。
そしてとうとう自分の番も来た、というだけのことです。まあ業務委託の立場で退職推奨に対して「自分の番」というのもおかしな話ですが、とにかく契約の解除ということになりました。僕は撤退作業の手伝いという形で9月末まで稼動していました。稼動初期に立ち上げから深く関わったサービスのクローズ作業をするのは感慨深かったです。
実は、RubyKaigiが終わった直後から、様々な条件付きで正社員として入る交渉をしていました。この交渉は本当に人員整理の直前までやっていたのですが、しかしまあ、白紙になりましたね。この条件に関しては、業務委託で稼動し続けた実績によって交渉していたものなので、そのまますぐ別の会社にこの条件でどうですか、ということはできません。なので本当に、残念な思いです。
職選びの観点で言うなら、たぶん自分はPythonやGoやJavaScriptの案件でもなんとか生活できるくらいのお金はいただけると思っています。それでもRubyの会社を選び続けるのは、Rubyでサービスを開発・運用し、コミュニティに投資している会社であれば、自分がRubyKaigiやKaigi on Railsのために使う時間のことを考慮してくれる(そのことで急に休みを入れることに理解がある)、そういうことへの理解があるからです。その点で、フルタイムRubyコミッタを抱えていたクックパッドは本当にいい会社でした。
個人的な気持ちの問題はどうあれ、クックパッドのサービスと会社のことは引き続き応援しています。残っているメンバーもまた優秀な人達ばかりなので、心配はしていません。
なお、次の稼動についてのお誘いに関しては不要です。
以上、個人の日記でした。
2023年09月08日
TL;DL
9/30 14時から開催の高専DJ部 #38 に来てください!!!
ことの経緯
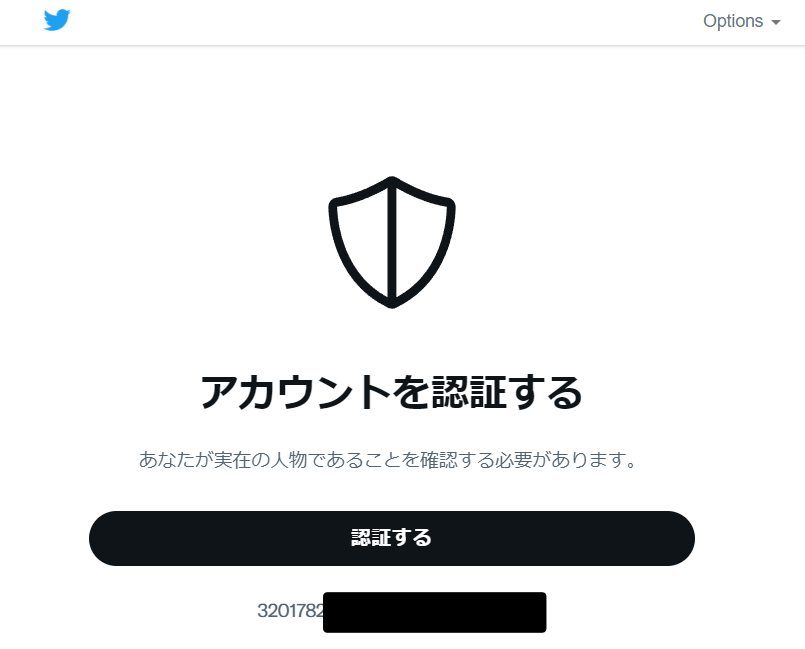
上記、高専DJ部の告知を行うために @kosendj にログインし、ユーザー名を変更した後に「あなたが実在の人物であることを確認する必要があります。」という表示になりました。
そして画像認証を行うのですが……これが何回やっても全然終わらない!!!!
15分くらい格闘して一旦あきらめ、@yu_suke1994 アカウントのほうで上記ツイートを行いました。そしたら同様の状態に……
ただ、どちらのアカウントも地道に認証をやっていたら突破できました。よかったですね。
あやしいと思っている点
どちらの場合も共通しているのは、「https://kosendj-bu.in のURLをツイートしたこと」です。あとハッシュタグでしょうか。いや、これが本当の原因かどうかはわかりませんが……
というわけで
何かあったら僕はこのあたりにいます。というか、最近は発言の主軸は自分の立てているMastodonに移しているつもりでいます。
コレクション
追記 (2023-09-08 08:50)
たぶんこれですね。
9/7現在、X(旧Twitter)にて名前/プロフィール変更をするとアカウント認証に飛ばされ認証通過しても「技術的な問題が発生したため」とログイン出来なくなるバグが発生中 - Togetter