2022年05月09日
Herokuの移行先を考える
今運用しているアプリ達をすぐにHeroku以外に移すということはしないまでも、競合となるプロダクトの調査をしておくことは(特に後発のものについては)機能面で実はこんなに便利なものがあったのか、と気づくことにもなったりするので、やっておいて損はないかと思いました。
比較対象について
比較する対象としては、インターネットで最近見かけるPaaSを選定しました。同様のことができるIaaSのコンポーネントとして、AWS FargateやGoogle Cloud Runがありますが、そのようなIaaSの一部として提供されるものについては今回は比較対象とはしません。
今回の比較対象は以下3つです。
deployするRailsアプリについて
HerokuにdeployするようなRailsアプリに必要な要素とは何かを考えたとき、まずDBが必要なのは当たり前として、Active Job(Sidekiq)やAction Cableを使いたいからRedisも使えてほしいです。もともとHeroku上にファイルはアップロードできないのでオブジェクトストレージは不要としました。
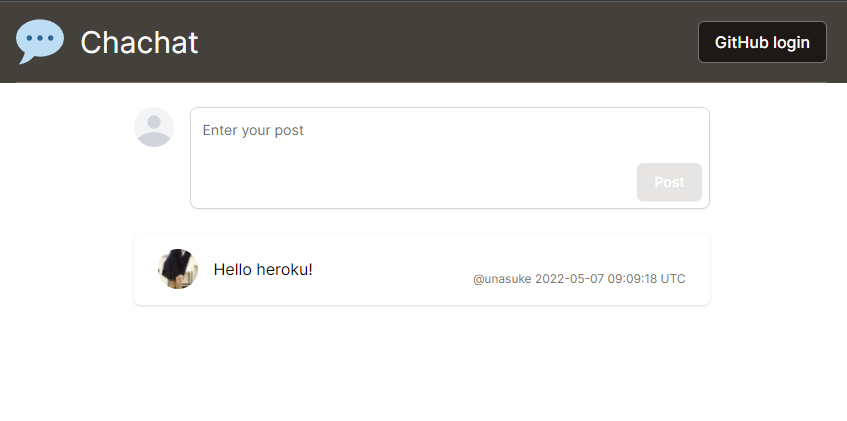
そこで、簡単なチャット(?)アプリを作りました。GitHubアカウントでログインすると100文字以内の文字列を投稿できます。ログイン状態に関わらず、投稿は自動的に更新されます。この仕組みは勉強も兼ねてTurbo Streamsで構築しました。
Render
公式にもHeroku対抗を謳っているだけあり、とてもHerokuに似たサービスです。僕自身、以前の記事で採用したことがあります。
Migrate from Heroku to Render | Render
実際、使い勝手としても、DBを作成すると環境変数 DATABASE_URL が自動的に追加されたりなどの挙動がHerokuと似ていて、新しく流儀を覚えなおす手間が少なくてよかったです。ただ、リソースは全てが一覧に出てきてアプリごとに管理するようなものではなかったです。deployはGitHubにpushすると自動で行われる感じでした。
Herokuにおける app.json と似たようなものとして、Blueprintという仕組みがあります。これによって、アプリで使用するリソース、接続情報などの環境変数、さらには接続を許可するIPアドレスなどをコードで管理できる(かつ、更新されたら自動で適用してくれる)のが便利でした。欲を言えばこのrender.yamlの書式が間違っている場合のエラーメッセージの親切さがもうちょっと欲しい1ところでした。
価格ですが、DBにHeroku Postgresのような無料プランがなく、自動的に3ヶ月後から月$7になってしまいます。RailsとRedisは稼動している時間が制限内であれば無料のまま動かせるようなので、HerokuのHobbyプランを使っていると考えれば、まあ……というところでしょうか。
また、今回deployしたアプリでは使いませんでしたが、Diskとminioを組み合わせたオブジェクトストレージを用意できるのは便利そうです。
Railway
サービスとしてはコンテナやbuildpackによってビルドしたサービスをdeployできるPaaSです。
Herokuみたいな"Deploy on Railway"ボタンが作れるのもいいですね。
https://railway.app/button
また、公式及びコミュニティから提供されているStarterがかなり豊富です。
https://railway.app/starters
使い勝手としては、UIはすごくよくできてて操作が快適なのはよかったです。様々な言語、フレームワークに対応しているというか汎用的で、反面Herokuと比較すると自分で設定しないといけないことが多いように感じました。リソースもprojectごとにまとめて管理できるのがHerokuっぽくて良いです。deployはGitHubにpushすると自動で行われる感じでした。regionは現時点で選択できず、US-Westのみです。"We plan to add additional regions.“ と公式FAQにはあります。
公式CLIが、npmやyarn経由でインストールしても実行可能なバイナリが配置されず、GitHub releaseからダウンロードしないといけなかったりちょっと不安ですが……
UIがすごくよくできている、というかよくできすぎていて、DBの中身が見れちゃうのは凄いと思います、がそんなに気軽に見れちゃていいの……?
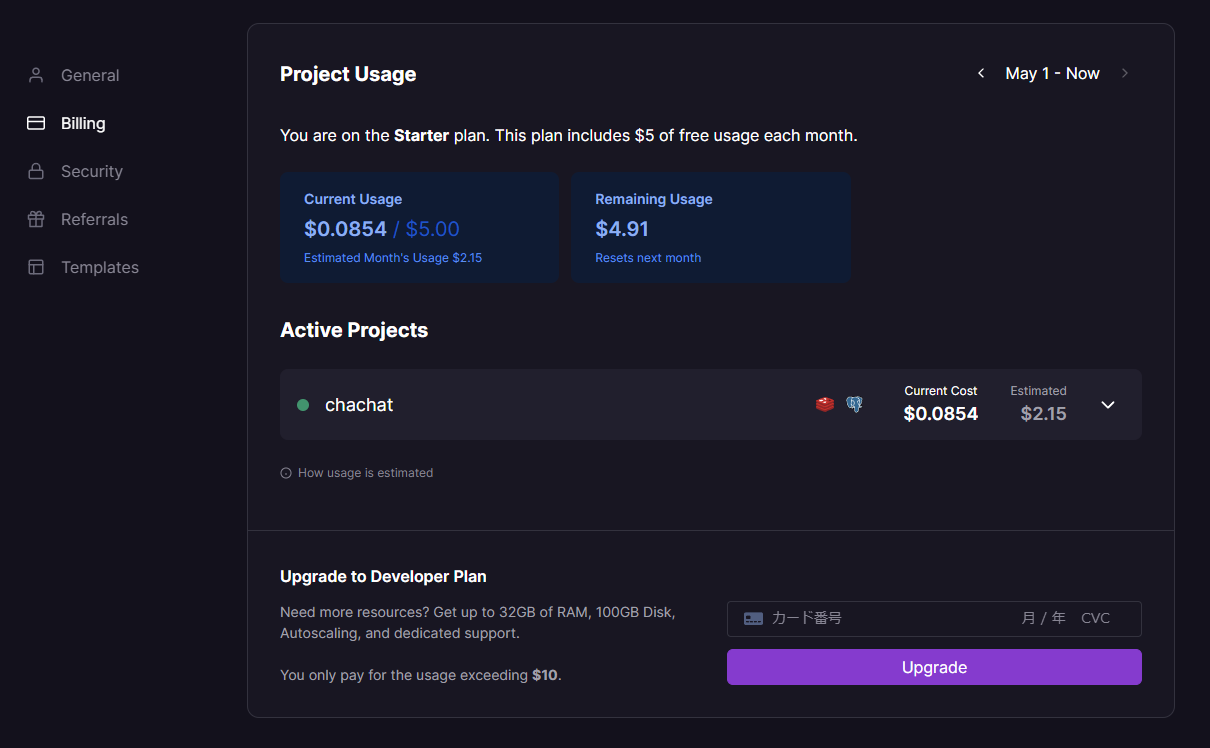
価格体系がpricingページからはちょっとわかりづらいです。
https://railway.app/pricing
dashboradのbilingを見るとどのくらいのコストになるかが予測で表示されるのが嬉しいです。
サービスの使い勝手とは関係ないですが、内部の実装はJob descriptionを見るとBorgとMesosの論文から独自に開発しているようでアツいです。
上記ツイートにぶら下げられているJob descriptionは今は見れません、以下に移動したようです。
https://www.notion.so/Open-Jobs-bdc641c4b72947f2ab1e09bea5362363
Fly.io
mizchiさんのこのブログ記事で聞いたことのあるという方は多いんじゃないでしょうか。僕もそのうちの一人です。
Edge Worker PaaS の fly.io が面白い - mizchi’s blog
現在は公式サイトに "Run your full stack apps (and databases!) all over the world. No ops required.” とあるように、マネージドなPostgreSQLも使えるようになっています。公式ドキュメントにもRailsをdeployする方法についての記載があります。
https://fly.io/docs/getting-started/rails/
感想としては、CLI (flyctl) から操作するのがメインだなという印象です。環境変数の追加も閲覧もWebからではできず、CLIからしか行うことができません。DBとしてPostgreSQLを追加するのはそんなに苦労しませんでしたが、Redisを追加するのに結構手間取りました(接続情報を自分でRails側に渡してあげないといけない)。deployも手元で flyctl deploy をするフローです。
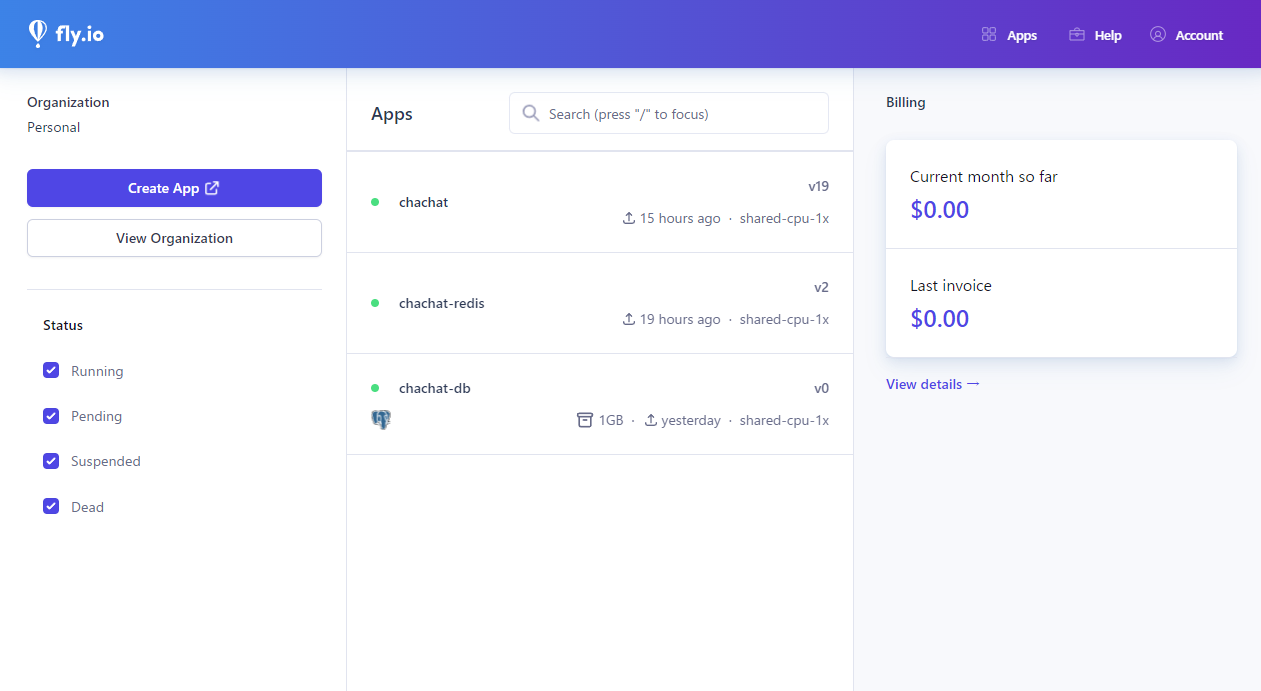
Herokuと比較した場合、東京リージョン(nrt)があるのが嬉しさでしょうか。
価格はこのようになっています。Herokuと比較してどうなるのかというのは一見ではわかりません。Usageを見ると現時点でのリソース消費量がわかります。
https://fly.io/docs/about/pricing/
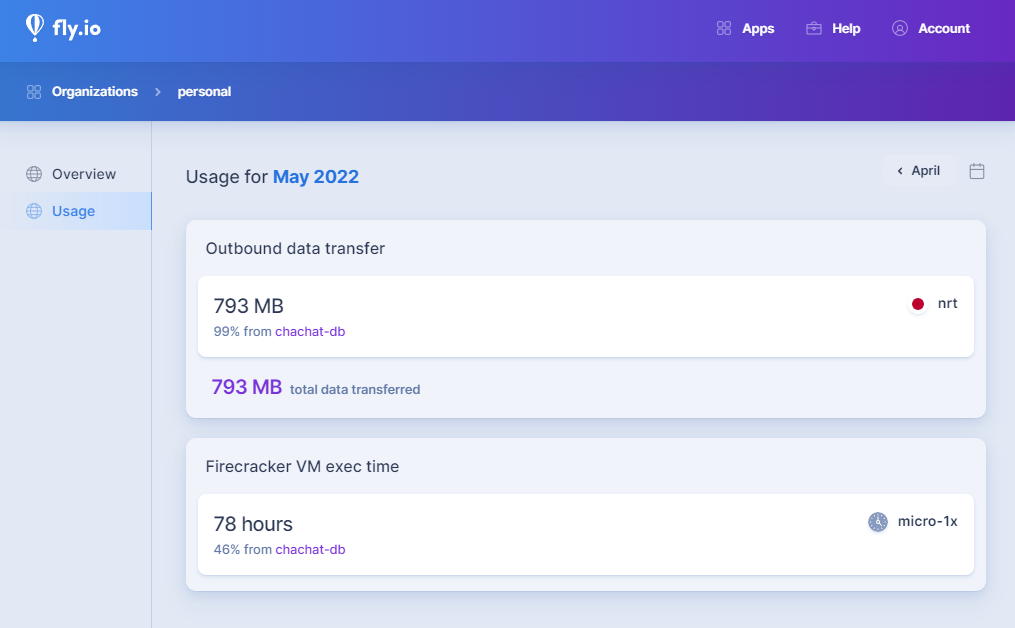
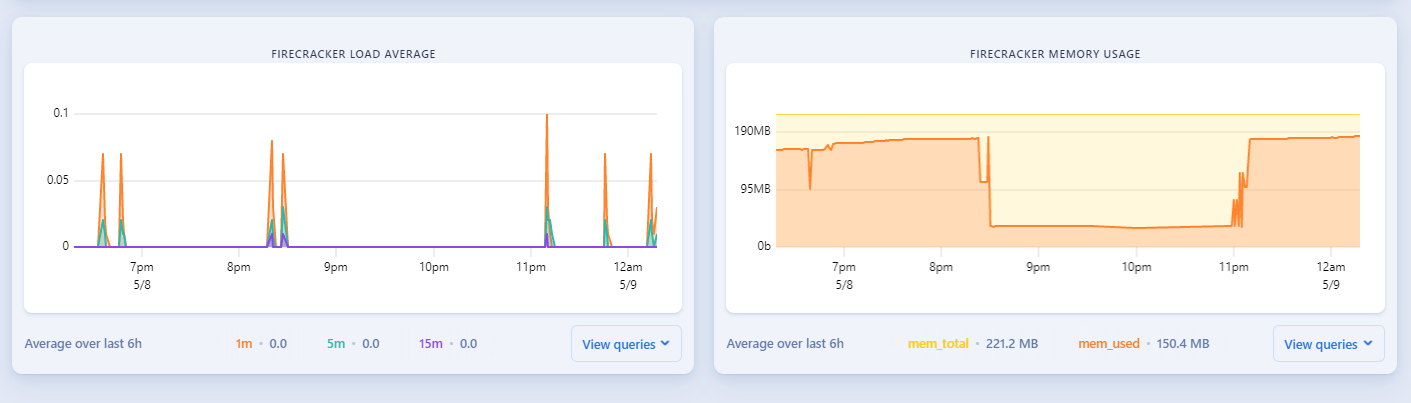
また、これはサービスの使い勝手とは関係ありませんが、アプリケーションがFirecracker上で動くのはアツいですね。メトリクスにもFirecrackerの状態が出ています。
https://fly.io/docs/reference/architecture/
総評
自分がHerokuに慣れているというのもあるせいか、どうしても、どれもHerokuより多少なりとも複雑だなあという印象です。これらで、僕が移行するなら以下の順で検討すると思います。
- Railway
- サービス毎にリソースをまとめて見られる、UIが快適なのが1番として選んだ理由
- Render
- Fly.io
また今回、Herokuから移行するなら、という点でサービスを選定しましたが、これは複数人で管理していく2ことも考慮しています。要するに、本気でお金をかけたくないのであれば複数のサービスを組み合わせて運用するのも選択肢としてあると思います。
個人開発のサービスをVPSからVercelとCloud Runに移行した話
今回deployしたアプリは今後数ヶ月ほどはそのまま動かしておいて価格がどうなるかを見たいと思います。その後は落とすかもしれませんし、データもバックアップはしません。
参考URL
2022年04月30日

msh3 as the third h3 backend……って何?
プログラマーの皆さんなら一度は使ったことのあるであろうcurlは、HTTP/3でリクエストを送ることができます。しかし、一般的に手に入るcurl、いわゆるOSのパッケージマネージャーから入手できるものでは不可能で、独自にビルドする必要があります。
(もし必要であれば、ここからHTTP/3が使えるcurl入りのdocker imageを入手できます https://github.com/unasuke/curl-http3 )
そのとき、外部のライブラリを組み込む必要があるのですが、これまではcloudflare/quicheか、nghttp3のどちらかを選ぶことができました。
2022年4月11日、その選択肢にMicrosoftの開発しているQUICプロトコル実装であるMsQuicが加わりました。
このツイートをしたNickさんはMsQuicの主要コントリビューターで、それを使いやすくするための薄いラッパーライブラリであるmsh3の作者であり、引用されているDanielさんはcurlの作者です。
じゃあビルドしてみよう
発表されたタイミングで、公式サイトのHTTP/3対応版のビルド方法についての記載が更新され、"msh3 (msquic) version" が追加されていました。
https://curl.se/docs/http3.html#msh3-msquic-version
それに従い、このようなDockerfileでビルドに成功しました。
FROM ubuntu:22.04 as base-fetch
RUN apt-get update && apt-get install -y git
FROM ubuntu:22.04 as base-build
RUN apt-get update && DEBIAN_FRONTEND="noninteractive" apt-get install -y build-essential pkg-config tzdata cmake
FROM base-fetch as fetch-msh3
WORKDIR /root
RUN git clone --recursive --depth 1 https://github.com/nibanks/msh3
FROM base-build as build-msh3
WORKDIR /root
COPY --from=fetch-msh3 /root/msh3 /root/msh3
WORKDIR /root/msh3/build
RUN cmake -G 'Unix Makefiles' -DCMAKE_BUILD_TYPE=RelWithDebInfo .. \
&& cmake --build . \
&& cmake --install .
FROM base-fetch as fetch-curl
WORKDIR /root
RUN git clone --depth 1 https://github.com/curl/curl
FROM base-build as build-curl
RUN apt-get update && DEBIAN_FRONTEND="noninteractive" apt-get install -y autoconf libtool libssl-dev
COPY --from=build-msh3 /usr/local /usr/local
COPY --from=fetch-curl /root/curl /root/curl
WORKDIR /root/curl
RUN autoreconf -fi
RUN ./configure LDFLAGS="-Wl,-rpath,/usr/local/lib" --with-msh3=/usr/local --with-openssl
RUN make -j`nproc`
RUN make install
FROM ubuntu:22.04 as executor
RUN apt update && apt install -y --no-install-recommends ca-certificates && rm -rf /var/lib/apt/lists/*
COPY --from=build-curl /etc/ld.so.conf.d/libc.conf /etc/ld.so.conf.d/libcurl.conf
COPY --from=build-curl /usr/local/lib/libcurl.so.4 /usr/local/lib/libcurl.so.4
COPY --from=build-curl /usr/local/lib/libmsh3.so /usr/local/lib/libmsh3.so
COPY --from=build-curl /usr/local/lib/libmsquic.so /usr/local/lib/libmsquic.so
COPY --from=build-curl /usr/local/bin/curl /usr/local/bin/curl
RUN ldconfig
CMD ["bash"]
https://github.com/unasuke/curl-http3/blob/53287f3b1f08b41b11067a27d787272ce566c2a7/msh3/Dockerfile
さて、出来上がったcurlでHTTP/3なサーバーに対してリクエストをしてみると、なんだかうまくいきません。具体的には、www.google.com にはHTTP/3でアクセスできるのですが、nghttp2.org:4433 にはアクセスできません。他にも、msh3のREADMEに記載のある outlook.office.com や www.cloudflare.com にはアクセスできるものの、quic.tech:8443 や quic.rocks:4433にはアクセスできません。
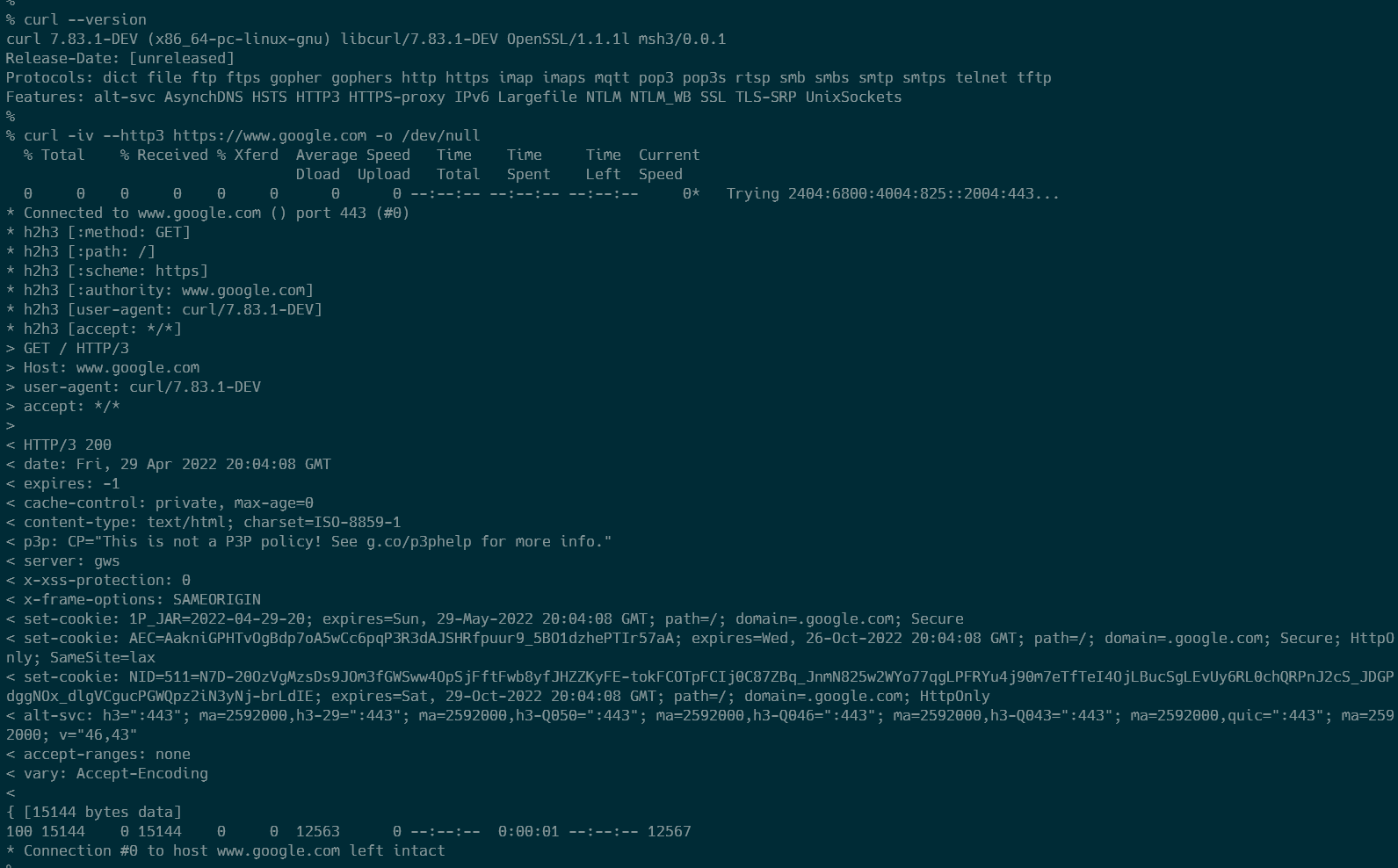
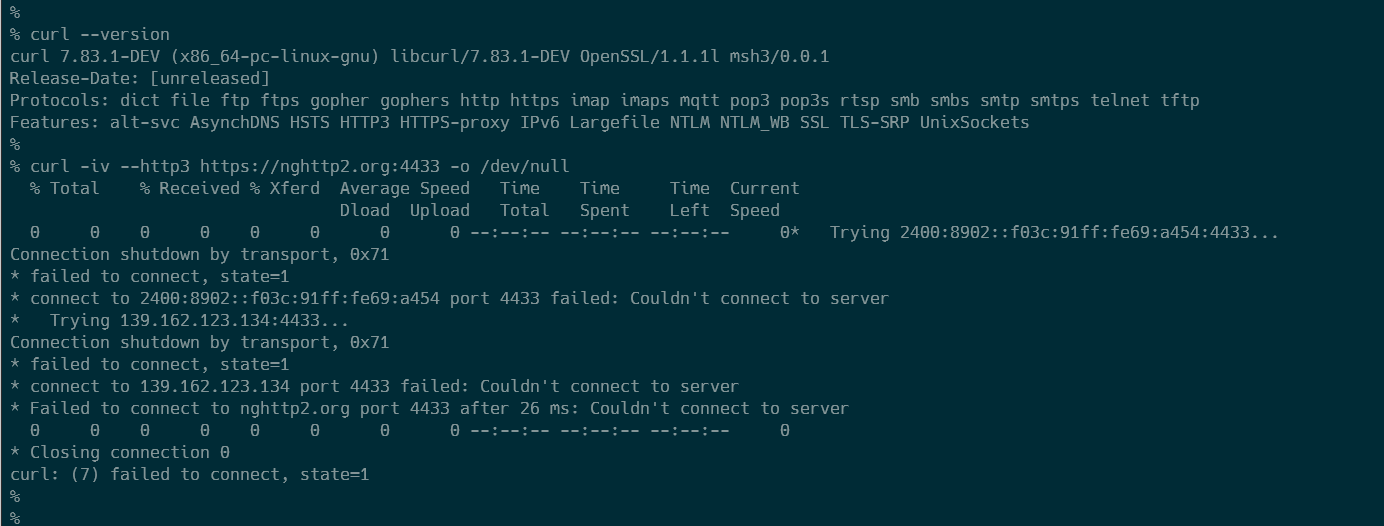
きいてみよう
よくわからなかったので、msh3の作者であるNickさんに聞いてみました(というか、Nickさんが僕のツイートに反応してくれました。大感謝です)
うーん、nghttp2.org:4433がHTTP/3をサポートしていないなんてことがあるのでしょうか?quiche版やnghttp3版ではリクエストができるので、調べてみることにしました。
切り分けてみよう
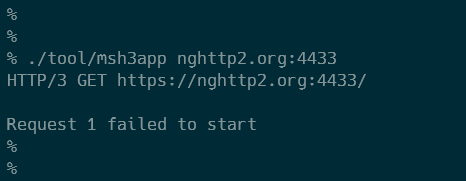
問題がどこにあるのか切り分けることにします。READMEによると、msh3には msh3app という試しにリクエストを送るためのプログラムがあります。これで nghttp2.org:4433へのリクエストができれば、僕がcurlを正しくビルドできていないことになります。
msh3appをビルドするには、以下のようなコマンドを実行します。
$ # msh3/build 以下で実行
$ cmake -G 'Unix Makefiles' -DMSH3_TOOL=on ..
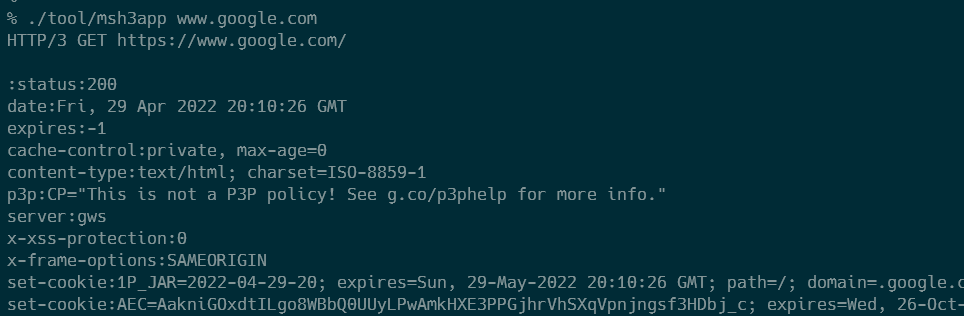
$ cmake --build .
これで build/tool/msh3appが生成されます。試しにwww.google.comと nghttp2.org:4433にリクエストを送ってみると、やはりnghttp2.org:4433へのリクエストは失敗しました。
では次に、MsQuicではどうでしょうか?MsQuicは、APIを使ったサンプルを用意してくれています。
https://github.com/microsoft/msquic/blob/main/src/tools/sample/sample.c
これをビルドする方法ですが、公式ドキュメントとしてビルドガイドがありました。
https://github.com/microsoft/msquic/blob/main/docs/BUILD.md
ここで、"Building with CMake" にあるような camke --build . ではこのサンプルコードはビルドされませんでした。恐らくCMakeの設定をいじらなければならないようですが、僕にはできそうにありません。なので、ビルドに使っていたUbuntu上にPowerShellをインストールし、 ./scripts/build.ps1 を実行することでビルドすることにしました。
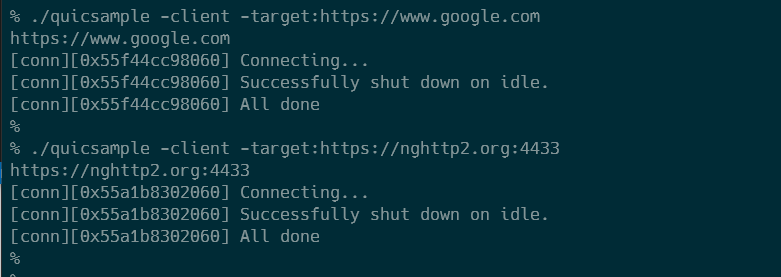
さて、結果ですが、www.google.comと nghttp2.org:4433 のどちらもHTTP/3でのリクエストは成功しました!ということは、msh3のどこかに何かの問題がありそうです。
msh3を探索してみよう
全部で87行と小さいので、msh3appの元となる tool/msh3_app.cpp の処理を追いかけてみることにします。
https://github.com/nibanks/msh3/blob/v0.2.0/tool/msh3_app.cpp
コマンドラインから受け取ったHostを使用してConnectionを作成している、という処理をしていそうな72行目、 MsH3ConnectionOpen の実装はどうなっているでしょうか。
auto Connection = MsH3ConnectionOpen(Api, Host, Unsecure);
MsH3ConnectionOpen の定義は lib/msh3.cpp の65行目からです。
https://github.com/nibanks/msh3/blob/v0.2.0/lib/msh3.cpp#L65-L81
extern "C"
MSH3_CONNECTION*
MSH3_CALL
MsH3ConnectionOpen(
MSH3_API* Handle,
const char* ServerName,
bool Unsecure
)
{
auto Reg = (MsQuicRegistration*)Handle;
auto H3 = new(std::nothrow) MsH3Connection(*Reg, ServerName, 443, Unsecure);
if (!H3 || QUIC_FAILED(H3->GetInitStatus())) {
delete H3;
return nullptr;
}
return (MSH3_CONNECTION*)H3;
}
ここで、 MsH3Connectionの引数として443を渡しています。ここが怪しいです。
さらに追いかけていくと、MsH3Connection は uint16_t でPortを受け取り、それを174行目でStartに渡しています。このStartの実体はわかりませんが、ともかくPortとして443を決め打ちで渡しているために、443番ポート以外でHTTP/3をホストしているアドレスにはリクエストできなかったのでしょう。
msh3を直してみよう
では、直してみることにします。
lib/msh3.cppのほうは簡単で、MsH3ConnectionOpenがPortを引数として受け取れるようにし、それをMsH3Connectionに渡すだけです。
問題は/tool/msh3_app.cpp のほうで、コマンドライン引数として受け取ったアドレスからhostとportを分離、portがなければ443として扱う、という処理を行う必要があります。Rubyであれば String#splitやString#rpartitionで簡単にできるのですが、C言語となるとそうはいきません。
まず、以下のように sscanf を用いて分割しようとしましたが、ホストとポートの区切りである : が %sの対象になってしまいうまく分割できません。
https://wandbox.org/permlink/2PC5Qqsesd6avigW
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *str = "nghttp2.org:4433";
char *givenHost = NULL;
int Port = 443;
int len = strlen(str);
givenHost = (char *)calloc(len + sizeof(char), sizeof(char));
if (givenHost == NULL) {
printf("failed to allocate memory!\n");
return -1;
}
int count = sscanf(str, "%s:%d", givenHost, &Port);
printf("givenHost :%s, port: %d, count: %d\n", givenHost, Port, count);
return 0;
}
悩んでいたところ、@castaneaさんに以下のStack Overflowを教えていただき、 %[^:] を使うことでhostとportを分割することができました。
scanf - C - sscanf not working - Stack Overflow https://stackoverflow.com/questions/7887003
https://wandbox.org/permlink/q16ugMxasUhgzdWJ
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *str = "nghttp2.org:4433";
char *givenHost = NULL;
int Port = 443;
int len = strlen(str);
givenHost = (char *)calloc(len + sizeof(char), sizeof(char));
if (givenHost == NULL) {
printf("failed to allocate memory!\n");
return -1;
}
int count = sscanf(str, "%[^:]:%d", givenHost, &Port);
printf("givenHost :%s, port: %d, count: %d\n", givenHost, Port, count);
return 0;
}
しかし、これでは不十分でした。というのも、MSVCでは安全性の観点からsscanfの使用は推奨されておらず、sscanf_s を使用しないと警告でWindows環境向けのコンパイルが失敗してしまいます。
よって、さらに #ifdef _WIN32 などしてWindows上とそれ以外の環境でsscanf_sかsscanfかを使い分けるようにしないといけません。
上記の過程を経て、msh3に対して作成したpull requestがこちらです。
Enable to connect to the host that hosting on non 443 port by unasuke · Pull Request #37 · nibanks/msh3
curl側を直してみよう
先ほどmsh3のAPIを変更したので、curl側にも修正が必要になります。
(実際には上で行ったmsh3への変更と同時並行で進めていました)
curl側でmsh3のAPIを使用しているのはlib/vquic/msh3.cになります。
https://github.com/curl/curl/blob/curl-7_83_0/lib/vquic/msh3.c
ここで、APIに変更を加えた MsH3ConnectionOpen を呼び出しているのは124行目です。
qs->conn = MsH3ConnectionOpen(qs->api, conn->host.name, unsecure);
なので、ここでport番号を渡してやればいいのですが……どこにリクエスト先のport番号があるのでしょうか?
これは #define DEBUG_HTTP3 1 などで色々な値を試し、conn->remote_port がそれだということがわかりました。なので、それを渡すだけでよさそうです!
- qs->conn = MsH3ConnectionOpen(qs->api, conn->host.name, unsecure);
+ qs->conn = MsH3ConnectionOpen(qs->api, conn->host.name, (uint16_t)conn->remote_port, unsecure);
Pass remote_port to MsH3ConnectionOpen by unasuke · Pull Request #8762 · curl/curl
という訳で、これもmergeされたことにより、msh3(MsQuic)版のcurlに任意のポート番号を渡してHTTP/3による通信ができるようになりました。
おわりに
C言語って難しいですね……
2022年03月30日
日本語版はこちら
tl;dr
I made this gem.
https://github.com/unasuke/omniauth-twitter2
This gem is one of the OmniAuth strategies for Twitter, using OAuth 2.0 for the authentication protocol.
We have omniauth-twitter gem. Why this gem?
Yes, the omniauth-twitter gem is a well-maintained, widely-used gem.
https://github.com/arunagw/omniauth-twitter
But, omniauth-twitter uses OAuth 1.0a.
Twitter OAuth 2.0 GA from 2021-12-15
When 2021-12-15, Twitter announced OAuth 2.0 General Availability.
And we can use “new fine-grained permission scopes” at the release.
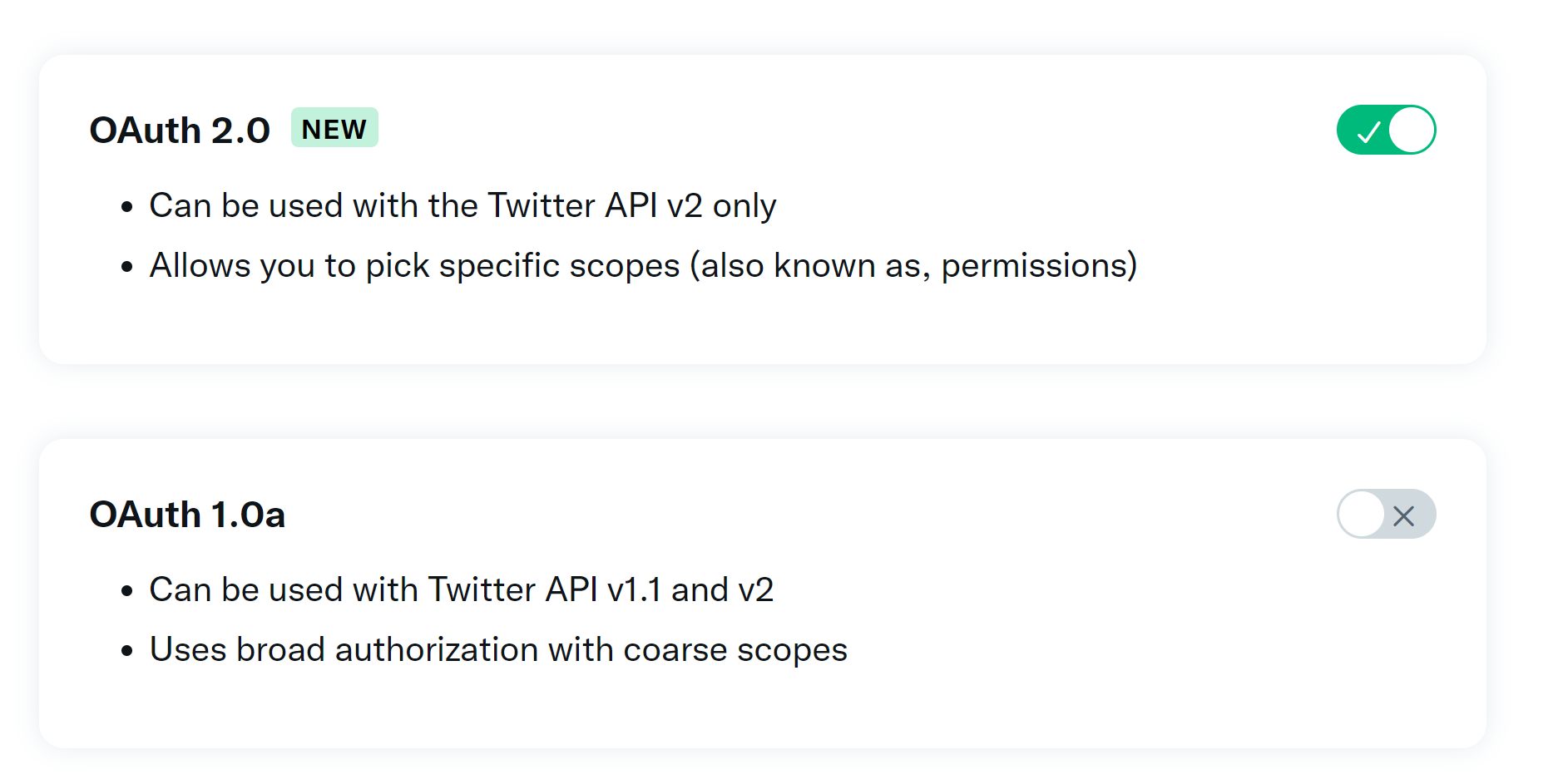
We could choose those three kinds of scopes in the older permission scope. That’s too rough.
- Read
- Read and Write
- Read and write and Direct message
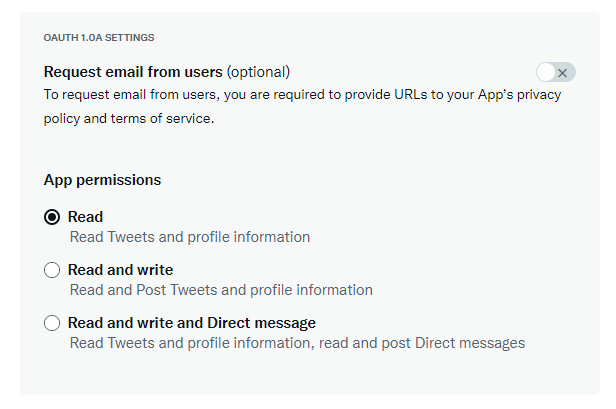
But now, We can choose enough permissions from the list on OAuth 2.0 (through Twitter API V2)
https://developer.twitter.com/en/docs/authentication/oauth-2-0/authorization-code
tweet.read, tweet.write, tweet.moderate.write, users.read, follows.read, follows.write, offline.access, space.read, mute.read, mute.write, like.read, like.write, list.read, list.write, block.read, block.write
OK, how to use twitter with OAuth 2.0 with my rails app?
I created a gem, “omniauth-twitter2”.
https://github.com/unasuke/omniauth-twitter2
This is one of the omniauth strategies, so it’s easy to integrate your rails app if you use omniauth (or devise?)
(“2” means OAuth 2.0, not means successor of “omniauth-twitter” gem. because the gem still working everywhare!)
And I have created a sample application that uses omniauth and omniauth-twitter2.
This app only signs in with twitter, but it’s enough to show how to implement “sign in with Twitter”.
Attention
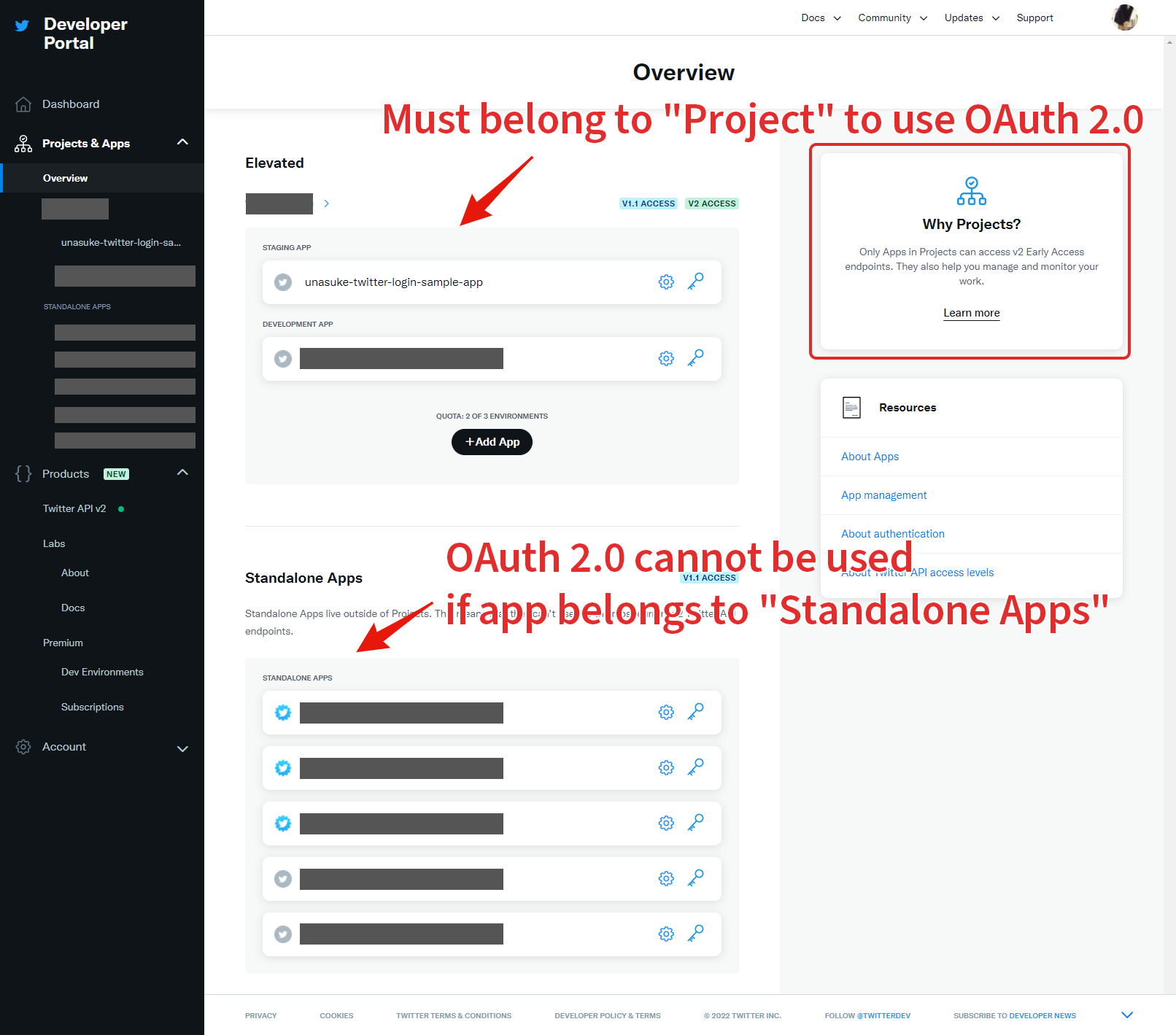
If you want to use OAuth 2.0 API in your twitter app, you should move your app to under “Project”. You can’t use OAuth 2.0 in your app if the app is still a “Standalone app”.
…And I’m not a specialist in the authentication. Please give me a pull request or issue if you found a bug.
2022年02月28日
tl;dr
unasuke/omniauth-twitter2: omniauth strategy for authenticating with twitter oauth2
↑ これをつくりました
Twitter認証、要求される権限がデカい問題
Twitter認証でログインできるWebアプリというものは色々あり、便利なので日々使っているという方は多いことでしょう。
しかしTwitter loginで要求される権限の粒度はこれまで以下の3つしかありませんでした。
- Read
- Read and Write
- Read and write and Direct message
これはあまりにも大雑把で、「要求される権限が広すぎる!」「いやいやこういう事情で……」というやりとりを見掛けたことは何度もあります。
このように解説する記事も多く存在します。
TwitterがOAuth 2.0をサポートした
さて2021年12月15日、TwitterはOAuth 2.0のサポートをGeneral Availabilityとしました。
Announcing OAuth 2.0 General Availability - Announcements - Twitter Developers
このタイミングで、
all developers can implement OAuth 2.0 and new fine-grained permission scopes in the Twitter developer porta
とあるように、"fine-grained" な、つまり適切な粒度での権限要求が可能となりました。
具体的にどのようなscopeで要求できるかというのは、記事作成時点で以下のようになっています。
https://developer.twitter.com/en/docs/authentication/oauth-2-0/authorization-code
tweet.read, tweet.write, tweet.moderate.write, users.read, follows.read, follows.write, offline.access, space.read, mute.read, mute.write, like.read, like.write, list.read, list.write, block.read, block.write
これまでと比較してとても細かく指定できることがわかります。
omniauth-twitter2 gem
さて、こうなるとOAuth 2.0でTwitter loginしたくなってきますね。Ruby及びRailsにおいてWebアプリでのSocial Accountによるログインといえば、OmniAuthがそのデファクトスタンダートと言えます。
https://github.com/omniauth/omniauth
ということで、OmniAuthのいちstrategyとして、omniauth-twitter2というgemを作りました。
unasuke/omniauth-twitter2: omniauth strategy for authenticating with twitter oauth2
使い方はよくあるOmniAuthのstrategyの導入と同様です。具体的にどのような挙動になるかはサンプルアプリを用意しました。
Client IDとClient Secret、その他OAuth 2.0の有効化については developer.twitter.comで行う必要があります。
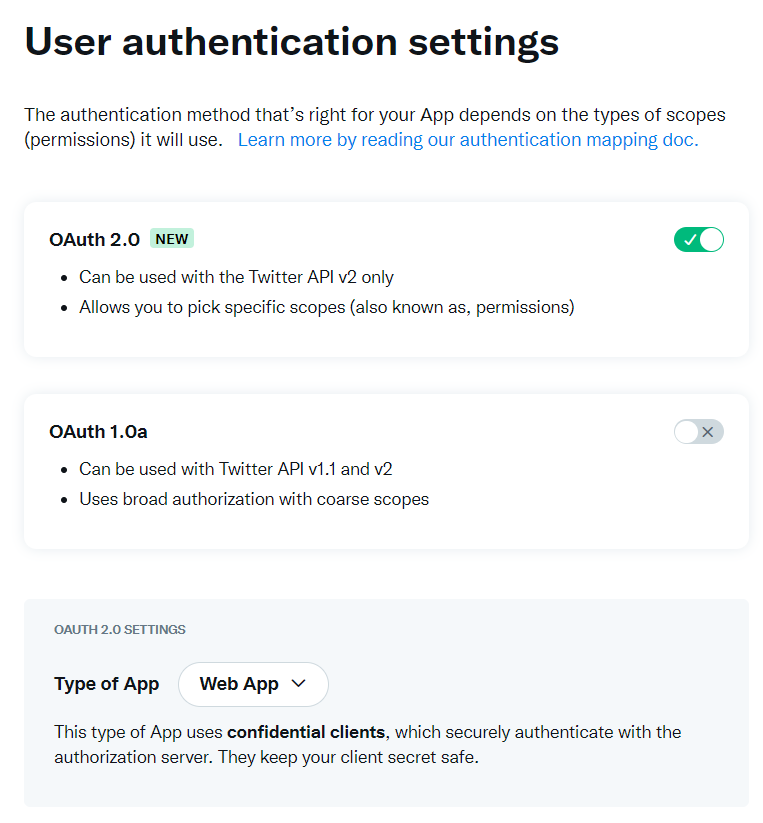
気をつけないといけないのは、OAuth 2.0 を有効にするためにはProjectを作成し、その下にAppを作成する必要があるという点です。Standalone AppsでもOauth 2.0 は有効にできそうなUIになっていますが、実際にはProjectに属していないといけないようです。
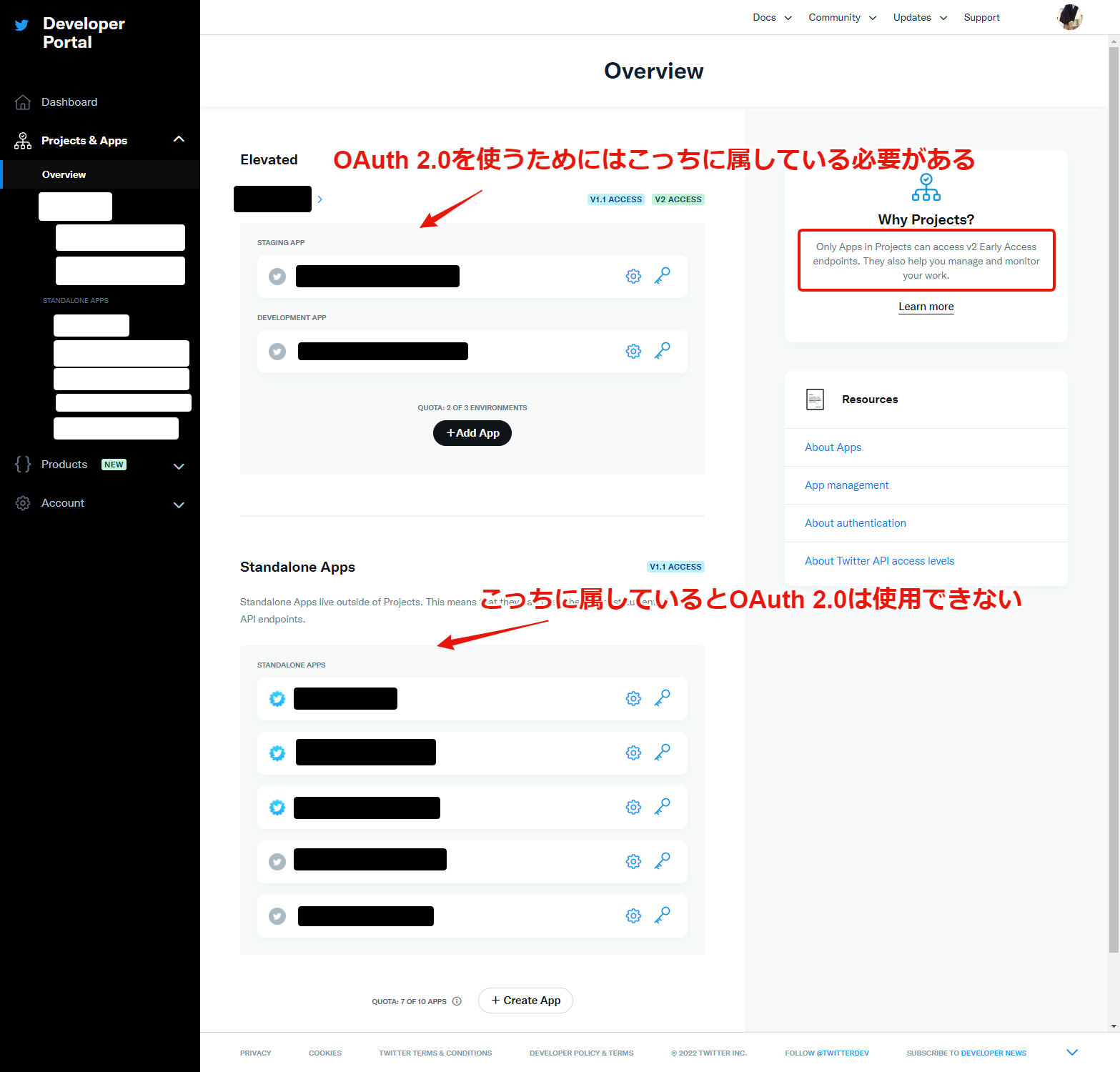
https://developer.twitter.com/en/docs/twitter-api/getting-started/about-twitter-api
そして、現時点で無料プランの最高となれるElevated1においては、Projectは1つ、その下に3つのAppを所属させることができますが、それ以上は Elevated+ にアップグレードしないとダメで、おそらく有料です。そしてまだcoming soonとなっています。
僕は認証、認可、OAuth 2.0の専門家ではないので、実装には誤りが含まれる可能性が高いです。皆さんのPull Requestをお待ちしています。
余談 Render.com について
今回サンプルアプリをホスティングする先として、render.comを選択しました。
公式WebサイトにHerokuとの比較を記載しているあたり、Herokuの立場を狙っているような感じがあります。今回renderを採用した最大の理由として、HTTP/2をサポートしていることです。
Heroku serves all content over HTTP/1.1. However, major browsers have supported HTTP/2 since 2015. Render serves all requests over HTTP/2 (and HTTP/3 where available), falling back to HTTP/1.1 for older clients. This minimizes simultaneous connections to your Render apps and reduces page load times for all your users.
https://render.com/render-vs-heroku-comparison
ただ一点、Free planにおいて、PostgreSQLが使用できるのですが、作成後90日経過すると停止するので再度作成しないといけない(ように見える、実際dashboard上でもpaid planへのupgradeを要求される)というのがネックです。
Render’s free database plan allows you to run a PostgreSQL database that automatically expires 90 days after creation.
https://render.com/docs/free
今回のサンプルアプリでは、DatabaseだけはHeroku Postgresを使うことにしました。
2022年01月09日
ただdeployしたかっただけなのに
僕のお手伝いしている、とある会社ではdeployをSlack botから行っていましたが、ある日そのbotが動かなくなっていました。Twitterでも少し話題になったので覚えていらっしゃる方もいると思います。
このとき何が起こっていたのか。前述したとある会社では、Slack bot frameworkとしてRubotyを、Slackとの通信にはruboty-slack_rtm gemを使っていました。
ではまず、こちらのSlack APIのChangelogをご覧ください。
If you still use rtm.connect or rtm.start to connect to Slack, you’ll notice that all WebSocket URLs now begin with wss://wss-primary.slack.com.
https://api.slack.com/changelog#changelogdate2021-11
以前はどのようなURLだったのかというのはわかりませんが、これに関連して、ruboty-slack_rtm gem側で以下のissueに記載のあるような問題が発生するようになりました。
OpenSSL::SSL::SSLError: SSLwrite at Heroku · Issue #46 · rosylilly/ruboty-slackrtm
どうやらSlackがWebSocketに使用するURLにて、TLS証明書にSNIが導入されたようです。そして、ruboty-slack_rtm gemがWebSocketでの通信のために使用しているwebsocket-client-simple gemがSNIを考慮できていないため、WebSocketでの通信が行えなくなってしまっている、ということのようでした。
一旦はslack-ruby-client gemを使うことで凌ぐことができましたが、websocket-client-simple gemにSNI対応が入ってくれると助かります。
さて、そのようなPull requrstは複数作成されていましたが、ownerであるところのshokaiさんの反応はありませんでした。
そこで思い切って聞いてみました。
すると、移管について前向きに検討していただけるとのことだったので、同様にRubotyを使っているruby-jp slackのGitHub organization下で管理するということになりました。
それについて、ruby-jpで行った会話の流れ1が以下になります。

やったこと
さて、そんなこんなでruby-jp以下に shokai/websocket-client-simple をforkし、gemをpublishする権限をいただいてから行ったことを以下にまとめました。
https://github.com/ruby-jp/websocket-client-simple
READMEの更新
まずは既存のrepositoryのREADMEを更新します。websocket-client-simple gemは歴史のあるrepositoryですから、 shokai/websocket-client-simple であるという共通認識があることでしょう。
そのため、「開発は ruby-jp/websocket-client-simple に移動したよ」ということをREADMEの上部、すぐ目に入る部分に記載するべきでしょう。(これは元々の shokai/websocket-client-simple に出す必要があります)
Update README (repo moved notice) by unasuke · Pull Request #42 · shokai/websocket-client-simple
merge後、既存のissue及びpull requestに対して「まだこの変更が必用なら ruby-jp/websocket-client-simple 側にお願いします」とコメントしました。
CIをGitHub Actionsに & 定期的に実行されるように
次に、CIが長期間実行されていないので、テストが通るかどうかを確認する必要があります。テストはGitHub Actionsで実行することにしました。
GitHub Actions by unasuke · Pull Request #1 · ruby-jp/websocket-client-simple
そして、CIが定期的に実行されるように設定しておきます。これにより、依存している別のgemの破壊的変更にすばやく気づくことができるようになります。
コードは変更せずにリリース
CIは整備しましたが、ここまでロジックは変更していません。最低限必要とするRubyのバージョンも変更していません。この状態で「開発は ruby-jp/websocket-client-simple に移動したよ」というメッセージをgemのinstall時に出すような変更を行い patch releaseを行いました。
Update gem metadata by unasuke · Pull Request #2 · ruby-jp/websocket-client-simple
このメッセージはそろそろ消そうかなと思います。homepage_url と source_code_url で事足りるためです。
Ruby 2.6.5以上を必須としてリリース
このリリースまでが、いわゆるmigration pathとしてのリリースです。リリース時点でメンテナンスされている、EOLになっていないRuby versionを下限とする制限を行ったリリースをしました。
Set minimum requied ruby version to 2.6.9 by unasuke · Pull Request #3 · ruby-jp/websocket-client-simple
SNI対応を行ってリリース
さて本題のSNI対応です。これは元々のrepositoryにpull requestを出している方が2人いらっしゃいました。その変更を見て僕がコードを編集して出すということもできますが、それはお二人にリスペクトがないと感じたため、その二人からpull requestが来るのを待つことにしました。
そしたらそのうちの一人であるfuyutonさんからpull reqを頂いたので、これを無事mergeしてリリースを行いました。やった!!!
Added to use SNI by fuyuton · Pull Request #6 · ruby-jp/websocket-client-simple
このあたりの変更を大晦日から年明けにかけてやっていました。いい年越しでした。
ruboty-slack_rtm側でwebsocket-client-simpleの最新版を使うように変更してもらう
ここでめでたしめでたし……とはいかず、ruboty-slack_rtm gem側が要求しているwebsocket-client-simpleが低いままなので問題は解決していません。
そのため、ruboty-slack_rtm側でSNI対応を行ったバージョンである0.5.0以上に依存するように変更を行ない、これをmergeしていただきました。
Use websocket-client-simple gem v0.5.0 or greater by unasuke · Pull Request #47 · rosylilly/ruboty-slack_rtm
これにて職場でのSlack botもmonkey patchなしで動くようになり、chatopsが無事にできるようになりました。めでたしめでたし。
余談 gemのowner権限について
さてこの度、Twitterでコミュニケーションしてgemの権限を頂くということを行いました。ところで、このような「owner権限のリクエスト」という機能がrubygems.orgに入っています。この機能では、作者がownerを引き受けてくれる人の募集、もしくはあるgemに対してのowner権限のリクエスト(こっちはgemのdownload数などに制限がある)を行うことができます。
ただ、まだリリースアナウンスはされていないようです。
追記 2022-01-10
shokaiさんの視点からの記事が出ているのでリンクを貼ります。
websocket-client-simpleをruby-jpに移管した - 橋本商会
追記 2022-05-01
Rubygems Adopationsについて公式の発表があったので更新しました。
2021年12月27日
昨年書いたサーバーサイドエンジニアとして2020年に使った技術1の2021年版となります。
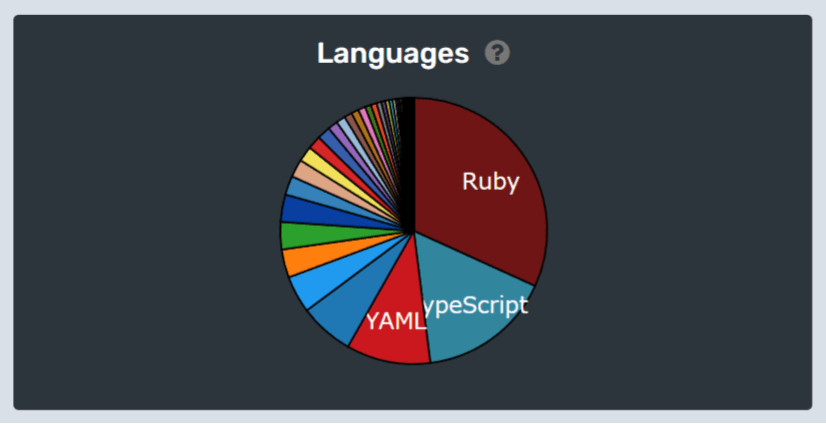
昨年と同じく、冒頭の画像はwakatimeによる2021年1月1日から12月26日までのプログラミング言語使用率です。2位はTypeScript、3位はYAML、4位はTerraformです。
立場
フリーランスで、主にRailsやAWSを使用しているサービスの運用、開発に関わっています。いくつもの会社を見てきた訳ではなく、数社に深く関わっている1都合上、視野が狭いかもしれません。(昨年と同じ)
今年公開している成果については以下です。
利用した技術一覧
昨年の記事では「特記事項があるもの」を太字にしていましたが、今回は去年からの差分を太字にしました。
- Language
- Ruby
- TypeScript
Python- Go
- Java
- Framework
- Rails
- React/
Vue
- Tailwind CSS
- Chakra UI
- Middleware/Infrastructure
- Docker
- PostgreSQL
- MySQL
- AWS (略)
- GCP (略)
- Terraform
- Kubernetes
- Kafka
- Cassandra
- CI
Travis CI- CircleCI
- GitHub Actions
- Monitoring
- Datadog
- Sentry
- RollBar
- Prometheus
- Grafana
- OS
- Editor (wakatimeによる使用時間合計順に並べました)
- VS Code
- IntelliJ Idea系
- Vim
- 概念的なもの
- WebRTC
- microservices
- REST API
- GraphQL
- QUIC
- その他
Ruby/QUIC
今年はRubyKaigi Takeout 2021に登壇することができました。どのような経緯で何について話したかは以下記事に書きました。
RubyKaigi Takeout 2021 で発表しました | うなすけとあれこれ
しかしRubyKaigi以降、Kaigi on Railsなど様々なイベントに関わっていたこともあり、今年はQUIC関連のことをこの発表以来全く触れられていない状況にあります。
自分への宿題としたOpenSSL gemのRactor関連タスクですが、Pull requestとして形に仕上げてmergeまで進められたのは以下の1つだけ2となっています。
Add test cases to OpenSSL::BN using ractor by unasuke · Pull Request #457 · ruby/openssl
QUICについては、Ruby、Ractorとは別に、手元に書きかけのものがあるので形にして出したいと思っています。
TypeScript
昨年の「Railsを主戦場としている自分が今後学ぶべき技術について(随筆)」にて以下のように書きました。
まずはTypeScript。これは先程の文脈の通り。Webアプリケーションに関わる開発者なら、既に「書けないとまずい」という域になりつつあるだろう。では、具体的に「書けないとまずい」とはどのレベルを指して言うのだろう。自分は、(中略) 例えばいくつかのライブラリを組み合せて0からWebアプリを構築するということが苦手だ、というかできない。
今年はElectronでPocketのリーダーアプリを作り始めたり、Rustと組み合わせてDeepLのデスクトップアプリを作ったりと、 「0から(Web)アプリを構築する」 ということがそれなりにできたのではないかと思います。どちらのアプリもまだまだ開発途中で足りてない機能は山程あるので、2022年も引き続き開発していきたいです。
Rust
TypeScriptの項でも触れた「DeepLのデスクトップアプリ」のメインプロセスはRustで書きました。Tauriというフレームワークを使っています。
これについて、なぜそういう選択をしたかについてはリリースしたときの記事に書きました。
DeepLのデスクトップアプリをRustとPreactとTailwind CSSでつくった | うなすけとあれこれ
Rustは概念の習得も書くのも難しいですが、The Rust Programming Language 日本語版をしっかり読み込めばなんとなくわかるようになる & rust-analyzerがとても優秀でどんどんコードを補完してくれる3ので書くのが楽しかったです。既存のプロダクトのRust版が出てくる理由がわかった気がします。
Kubernetes/Prometheus/Grafana
公開している成果にも挙げたように、「Black Game Streaming Engine v2」をKuberntes上に構築しました。
昨年「Fargate/ECSで要件を十分に満たすことができる」と書いたように、インフラをKubernetesに移行した記事に対し「Kubernetesである必要がないのでは」と言われたりすることもありますが、これはまさにKubernetesを採用する必要があった要件です。詳しくは以下の発表記事をご覧ください。
僕がこのプロジェクトで主に担当したのは監視周りの構築になります。PrometheusとGrafanaの準備を行いました。Grafanaの前段にoauth2-proxyを置いてアクセス制限をしたり、cert-managerで証明書の自動更新をしたりという作業が地味に面倒で大変だった思い出があります。
Java/Kafka/Cassandra
去年から増えたもののうち、めちゃくちゃ企業色の強いものです。項目として取り上げましたが、ヘビーに関わったということではなく「やっていくぞ!」という流れがあり書籍を何冊か購入し読書会をやったり、ハンズオンをしたりしてチーム内での経験値を上げている段階です。購入した本は以下になります。
来年がんばりたいこと
Ruby/QUIC
やったことでも書いたように、RubyでQUICを話せるようにしてみたい、そのために小さくても一歩一歩前に進んでいきたいです。具体的にはInitial packet以降のフローに対応する、OpenSSL gemのRactorテストコードを書いていく、などです。あと書きかけのプロダクトも世に出したいです。
TypeScript
ElectronによるPocketのリーダーアプリですが、今年後半は全く言っていいほど動けていませんでした。デザイナーさんにお願いしてアイコンやUIデザインについてのアドバイスを頂いたので、そのあたりをキレイにしてリリースしたいです。
DeepLクライアントアプリも、突貫で作ったのでローディングのスピナー表示などをやっていきたいと思います。
また急に作りはじめたVJアプリについても、高専DJ部開催のタイミングだけになるとは思いますが使いやすく、良い映像を出せるように細々とやっていきたいです。
Community (Kaigi on Rails)
Kaigi on Railsに関しては引き続きオーガナイザーの一員として関わるのみでなく、できればProposalを提出したいです。ネタというかこういうことについて話したいというアイデアはありますが、話せるようになるまでコードをいっぱい書く必要があるので、コードをいっぱい書きたいと思います。
English
せっかくDeepLのデスクトップアプリを作ったり、QUIC関連のことをやったりしていて、これらは別に内容が日本に閉じたものではないので、英語で情報発信をしていくということをやっていきたいです。そう思うようになったきっかけの1つは、角谷さんのKaigi on Rails 2021での発表があります。

Polishing on “Polished Ruby Programming” #kaigionrails / kaigionrails 2021 - Speaker Deck
まとめ
がんばります。
2021年12月10日
アンサーブログ
これは Ruby についてカジュアルに議論できる場が欲しい - 虚無庵 というブログのアンサー的なものです。
上記ブログ記事で、甚六さんが
そもそもで”本当にカジュアルに話題を振って良いのか?”どうか分かっていない
とおっしゃられてますが、僕は良いと思います。そう思う理由を以下に続けます。
書いている人間の立場
僕はItamaeというRuby gemのメンテナ1です。Itamaeは構成管理ツールであり、同様のものはChefやAnsibleが挙げられます。
2018年からメンテナの一員となり、issue/pull requestへの対応、新しいバージョンのリリースやSlackでのコミュニケーションをやっていってます。
Itamaeのメンテナになりました | うなすけとあれこれ
もちろんRubyとは関わっているメンバーやコードベースの規模が大きく異りますが、Rubyと同様にOSSであり、僕はそのメンテナなのでこのテーマについてメンテナ側の立場で発言する資格はあると思っています。
要するに、まず結論
OSSのメンテナが「やりたい」と思っていることがあり、それについて外部から「やってほしい」や「手伝います」という声が上がってくれば優先度が上がる、というだけのことなんじゃないかと思います。
もちろん、「やってほしい」という要望は、そのOSS project固有のやりかたに則って上げる必要があるでしょう。これについてはsongmuさんが以前こんなことをおっしゃっていました。
そのプロジェクトのやりかたに則してさえいれば、あとは度胸、やるだけなんじゃないかなと。この場合は、まずRuby-dev office hourで話題に挙げる、でしょうか。
なぜそう思うのか、実際の事例
そもそも皆さんはItamaeをご存知でしょうか。最近はもっぱらコンテナ型仮想化技術が人気になったのもあり、インスタンスのprovisioningという行為を行うことは減ってきているのではないかと思います。しかし不要になったわけではありません。最低限Dockerが動くmachine imageを作ったり、自分の使うPCの環境構築のためなどで構成管理ツールは現役です。
現在、構成管理ツールとして主流なのはAnshibleかと思いますが、Itamaeも便利です。特にRubyに慣れた人にとっては使いやすい2でしょう。
しかし知名度やユーザーはAnsibleと比較すると今一つ、というかとても少ないのではないかと言わざるをえません。理由の一つとして、「ドキュメントが少ない」のではないかという仮説を僕は持っています。そうでなくても、Itamaeのドキュメントは公式GitHub reopositoryにwikiがあるくらいで、メンテナが言うのもなんですが、積極的にメンテナンスされているとは言い難いです。GitHub wikiなので、Pull Requestを受け付けることもできません。
https://github.com/itamae-kitchen/itamae/wiki
まとまった記事としても、作者のryotaraiさんによるGihyoでの連載があるくらいで、これも2015年に書かれたものですし、日本語の資料しかありません。内容が陳腐化したということはありませんが、公式でもっとリソースを用意できたらなというのはずっと考えていました。
Itamaeが構成管理を仕込みます! ~新進気鋭の国産・構成管理ツール~:連載|gihyo.jp … 技術評論社
そうやってやりたい気持ちは抱えているだけで、他のやりたいことに手一杯で全然手を動かすことができていませんでした。そこに、海外の方から声がかかりました。「GitHub wikiにこのコードサンプルを追加してほしい」「英語ドキュメントを充実させたい、その手伝いがしたいが、何かできることはないですか?」と。
言うなれば、僕が抱えていた課題感は、これまでは僕しか課題に思っていないものでした。しかし利用者からの要望があるということで、それに取り組む価値があるということがわかったのです。
今回甚六さんが課題に思っているのはRubyのパーサーについての保守性のことです。
個人的に Ruby parser についてまとめてみた - 虚無庵
この問題についても同じようなことが言えるのではないかと思っています。何とかしなきゃいけないとは思っているけど、本当に困っている人が居るかどうかわからない。なので優先度を上げる理由がない。手を動かしてくれる人がいるのであれば……
メンテナ側としての意見
ユーザーからの意見や要望というのは、基本的にはありがたいものです。機能要望、bug fixなどをどのように連絡してほしいかというのは、projectのやりかたに従っているのであれば怒られるものではないはずですし、project側はやりかたを明記しておくべきでしょう。
また、以下の記事に言及して過度に忖度、萎縮されているように感じました。
「issueを立てるな!」 - Qiita
この記事はタイトルこそ「issueを立てるな」であり、OSSはissueひとつで崩壊しかねない、儚いものだと述べています。ただ、この記事で問題としているのは、正当な手順を踏まないissueの作成であり、このコンテキストにおいてはあてはまらないと考えます。ちゃんとメンテナの方々の労力を思いやることができ、projectのやりかたを踏まえて要望を挙げるのであれば、何も萎縮することはないと思います。
ただ、何度も同じ話題が出てきては立ち消えてしまうのであれば、それは別の問題がありそう3なので一旦立ち止まるといいのかもしれません。
今回の話であれば、まずRuby-dev office hourで話題に挙げるというのは全然アリなんじゃないかと思います。中の人でもなんでもないですが、一度参加した感じだとそういう話題が忌避されることはないでしょう。
また、卜部さんのSlackタバコ部屋問題については、そこで決めるから問題になるのであって、何が問題なのかふわふわした状態でticketを切るより、一旦closedな場でもいいので、議論となる点をまとめてから公開の場で話題に挙げる、というのは全然問題ないと考えます。
コントリビューターとしての意見
Rubyほどの大きなプロジェクトに対して意見を提案するのは気が引けるというのはとてもよくわかります。とはいえ、これはもうやるかやらないかなので、「やるぞ」という気持ちを作るしかないと思います。
口頭で Ruby のことを話さなければならないので自分にはハードルが高い
についてですが、hackmdに事前に内容を書いておけること、以前の記事がとてもよくまとまっていることから、話す内容、想定質問については準備しておいて臨めばいいのではないかと思います。研究発表の場でもないので、考えが甘いことで詰められることもないでしょうし。
英語については、僕も同意見です。自信は全くないです。しかし、OSSをやっていく上で必用な英語のスキルというのは、読みと書きの比重がとても大きいです。つまりこの2つが最低限なんとかなればいいので、あとは機械翻訳に頼ればいいと思います。ただ、機械翻訳の結果の英文がおかしなことになっていないかを判断するための最低限の英語力は必用だと思うので、それは勉強しかないでしょう。僕はDuolingoをやっています。OSS活動の際に書く英文ですが、「これDuolingoでやった文型だな」と感じることはそれなりにあります。
まとめ
今のRubyコミュニティで、Ruby-dev office hour及びruby-jp slack以上にカジュアルに議論できる場はなく4、今後もできないと思います。なので、あとは、がんばってください!!
(ところで例えばPEGに置き換えるとして、PEGでRubyの文法って表現できるんですか?)
2021年11月30日
これはなに
DeepLのAPI keyを使って翻訳を行う、DeepLが公式に提供しているデスクトップアプリのようなものの個人開発版です。
UI部分にPreactとTailwind CSS (Tailwind UI)、アプリケーションの土台やAPIとの通信部分にはRust (Tauri)を使っています。
名前は、DeepLのアプリなので、 ^d.*p.*l.*$ にマッチする英単語から適当に選んで “deplore” としました。
動機
英語は英語のまま理解できるのがもちろん一番いいのですが、長すぎる英文の概要だけでもサッとつかみたい場合などは機械翻訳は非常に役立ちます。
近年、機械翻訳ではDeepLの精度がとても素晴らしく、僕もPro planを契約して日常的に使っていました。しかし、DeepLの個人向けライセンスは、一度に1端末からしかアクセスできないという制限があります。
個人向けのライセンスでは、1名のみDeepL Proをご利用いただけます。この1名は、複数のデバイスからDeepL Proにアクセスできますが、一度に1つのデバイスからのみアクセスできます。
個人向けプランとチーム向けプランの違い – DeepLヘルプセンター
チーム向けのプランにすると料金は2名からとなってしまい、価格が倍となってしまいます。これはつらいです。
複数端末でDeepLを使っているとこの制限にとても頻繁にひっかかり、フラストレーションが溜まります。一時期、ログインセッションが切れる度にツイートしていました。
from:yu_suke1994 deepl session - Twitter検索 / Twitter
さすがにしんどくなったので、API planを契約して同じようなことができるデスクトップアプリを作ることにしました。
Why tauri, what’s tauri
アプリケーションの作成にはTauriを使うことにしました。
Build smaller, faster, and more secure desktop applications with a web frontend | Tauri Studio
Tauriは、Rust製のデスクトップアプリケーションフレームワークで、UIの部分にはWeb技術を使用することができます。
当初はElectronでサッと作れればいいかな?と思いましたが、以下のような理由からTauri(Rust)を採用することにしました。
- やることが小さい
- Blink依存の何かを書くことがない
- Blinkのみを想定したコードを書く必要はなさそう
- CSSでのStylingやJavaScriptの挙動について複雑なことをしない
Tauriは、OSのwebviewを使用するため、Blinkを同梱するElectronよりバンドルサイズを削減することができます。
もっともその分、WebKitやBlinkでの挙動の違いを考慮する必用はありますが、EdgeがBlinkベースになったのでそこまで大変ということもないと判断しました。
あと、Rustを書いてみたかった1、という理由もあります。
その他技術選定
フロントエンド部分については、Preactを選択しました。Tauriのフットプリントの軽さを活かしたかったのと、Preactで困ることがないだろうという理由です。
https://preactjs.com/
状態管理に関しては、新しめであり、使ってみたかったという理由でRecoilを選択しました。
https://recoiljs.org/
デザインに関しては、Tailwind CSS、と言うよりTailwind UIを選択(購入)しました。Tailwind CSSを使ってみたかったのと、出来合いのコンポーネントの質が非常に良いからです。
また、bundlingに関してはその速さが界隈で話題なのもあり、Viteを選択しました。
https://vitejs.dev/
ちなみにこれらは、 yarn create tauri-app から create-vite → preact-ts という選択をすることで簡単に導入することができました。
苦労部分
とにかくRustの並行処理、所有権のあたりが壊滅的にわかりませんでした。rust-analyzerとGitHub Copilotにおんぶにだっこ状態でコードを書いていました。"The Rust Programming Language" には現在主流となっている(?)Futureについての入門的記載が見当らず、またTauriのdocumentやRustのdocumentの土地勘がなく、reqwestを用いた非同期なAPI requestを行うまでにとても苦労しました。
開発に、大体1ヶ月くらいはかかりました。Rustの記事をとにかく読み漁っていました。
コントリビューション歓迎
RustもReactも習熟しているとは言い難いので、ある程度の経験がある方から見るとなんでこんなことになってるんだ!!なコードだらけかと思います。またエラー処理や、APIのレスポンス待ちにspinnerを出したりなど足りてない機能が沢山あります。皆さんのコントリビューションをお待ちしています!!!!!
2021年10月31日
はじめに
これは 2021 年 10 月 31 日に開催された Brain Hackers Meetup #1 での発表内容を再構成したものです。
僕のスキルと Brain Hackers コミュニティ
Brain Hackers は、SHARP の電子辞書 “Brain” シリーズの改造や、ソフトウェアの開発に興味がある人々のためのコミュニティです。
https://github.com/brain-hackers/README
とあるように、ハードウェアの改造がメインの目的となるコミュニティです。僕も参加しているのですが、僕はあまりその方面の知識がありません。というので、僕にできることで何か面白そうなことができないかというのを考えていました。
Brainux は IoT デバイスになれるのか?
ある日、「Brainux で IoT っぽいことってできないのかな」と思ったことが始まりでした。日々追い掛けている Kubernetes 関係の情報で、 KubeEdge というものがあったなということも思い出し、これと Brainux を組み合わせられないかというのを思いつきました。
KubeEdge について
KubeEdge の詳細な説明はしませんが、とにかく Edge device を Kubernetes cluster に参加させることができるもののようです。これを Brainux に導入できたら何か面白いことができるのではないかと思いました。
KubeEdge を setup する
KubeEdge をセットアップするための方法は、 https://kubeedge.io/en/docs/setup/keadm/ に記載があります。これをやっていきます。
さて、手順に “Setup Cloud Side (KubeEdge Master Node)” という項目があります。ここからわかるように、KubeEdge の master node となるインスタンスで何か作業を行う必要があり、となると Master node に入って作業をるする必要がある、すなわち Master node を操作できるようになっていなければなりません。
よって、GKE や EKS といった Managed Kubernetes service には導入できず、自分で Kubernetes cluster を構築する必要がありそうです。
kubeadm で Kubernetes cluster を構築する
早速 kubeadm を使用して、GCP 上に Kubernetes cluster を構築していきます。
一点注意が必要なのは、最新の KubeEdge の Release1 は、現時点で素直に kubeadm を apt から install して入る Kubernetes の version 1.22 系ではうまく動きません。そのため、 sudo apt install -y kubelet=1.21.1-00 kubeadm=1.21.1-00 kubectl=1.21.1-00 などで 1.21 系をインストール、構築する必要があります。
さて、これで Kubernetes cluster を構築することができました(ということにします。詳細については触れません)。
keadm init を実行する
https://kubeedge.io/en/docs/setup/keadm/#setup-cloud-side-kubeedge-master-node
さて、 Kubernetes cluster ができあがったので、 keadm を実行して KubeEdge を構築します。
ここまでで Cloud Side での setup が完了しました。
Brainux 上で keadm join を実行する
ここから、 Edge Side での setup を行っていきます。適当に arm 向けのバイナリを実行すると、以下のように “Illegal instruction” というエラーになってしまいます。
これは、いわゆる現代において何も考えずに Go で Arm 向けのバイナリをビルドすると、それは ARMv7 向けのバイナリとしてビルドされます。ですが、現時点で僕が Braniux を動かしている PW-SH2 は ARMv5 であり、つまり動きません。
https://github.com/golang/go/wiki/GoArm
KubeEdge をビルドする
なので、手元で git clone してビルドしようと思ったのですが…… clone 中に電池が切れてしまい、その後起動しなくなってしまいました。
Part 2 について
未定です。
2021年10月24日
Kaigi on Rails 2021 おつかれさまでした
Kaigi on Rails 2021 に参加していただいた皆様、素晴らしい発表をしてくださった発表者の皆様、そして Proposal を提出してくださった皆様、協賛していただいたスポンサーの皆様、本当にありがとうございます。今年も Kaigi on Rails を開催することができました。
まだまだ残っている作業は多いのですが、ひとまず本編終了ということで振り返りを書こうと思います。
担当範囲
- cfp-app のお世話
- ドメイン周り
- 動画編集
- 当日配信(バックアップ)
- 雑用少々
大体昨年と同じような範囲を担当しました。
Kaigi on Rails STAY HOME Edition 配信の裏側
配信については昨年と少し変わって、OBS から配信するマシンと Zoom に入場して映像・音声を拾うマシンを完全に別にしました。こうすることによって Slack など他アプリの音がまちがって入ることのない体制を組むことができました。
昨年から cfp-app は用意したかったのですが、様々な事情1により導入は今年からとなってしまいました。また、cfp-app はやっぱり便利だけど、これまたとある事情1により今年は使いこなすことができませんでした。来年に向けてやっていく気持ちがあります。
オンラインカンファレンスと “手応え”
終わってみれば Doorkeeper の参加者登録は 700 人超というすごい数字になりました。YouTube の配信も同時視聴者数が 200 人超と、とても多くの方々に参加していただけたと思います。
しかし今回、準備から開催終了まで、スタッフは一切リアルで集合することはありませんでした。
また、実際に会場を抑えて開催するイベントにおいて、数百人が集まるというのは、それを実際に “見る” ことができます。
ですが、Kaigi on Rails 2021 の本編運営においては、言ってしまえばパソコンの前でポチポチしているだけ2で、家から一歩も出ずに終わってしまいました。
これは技術が発展したからだという良い面ももちろんありますが、どうにもこれまでのスタッフ業と比較すると「やった感」があまりないというか、本当にみんな来てくれて、楽しんでくれたんだろうか、そういうイベントをやれていたんだろうかという気持ちが残ります。
なので、皆さんの Twitter での投稿や reBako、SpatialChat 、感想ブログでの反応をありがたく頂いています。
Next
準備期間中は先輩イベントである RubyKaigi の取り組みからの着想であったり、他にも様々なアイデアが出てきましたが、どうにも開催までの期間では他にやることも多く中々手が出せていませんでした。
来年というか次回の Kaigi on Rails でどれだけお手伝いできるかはわかりませんが、しばらく(Kaigi on Rails の運営業が)ゆっくりできる時間に細々と手を動かしていけたらいいなと思っています。
そして、もしかしたら来年の開催ではリアル会場で開催できるのか、できないのか……という情勢になってきています。そうなったとき、どこまでオンライン重点で準備をしていくべきか3というのが全く見えていません。難しいですね。
この記事は The Mark 65 によって書かれました。