UTF-8 の文字列をできる限り Shift_JIS に変換したい(実践編)
先日、きりきりやままさんがこのような記事を公開していました
UTF-8 の文字列をできる限り Shift_JIS に変換したい - きりきりやま
それでは実際にそのような文字列変換を行うにはどうすればよいのか、またコメントでiconvについて触れられていたので、この記事ではUnicodeにおけるNFKC正規化をどうやって行うのか試してみることにしました。
追記
- GoとPythonとJavaScriptでの例を足しました。またいくつかのscriptにおいてブラウザ上で実行できるURLを添付しました。 (2020-08-17 16:22)
- “Go” に表記を統一しました。 (2020-08-17 17:00)
Ruby
僕にとって文字列処理といえばRubyなので、まずは以下のようなscriptを書いてみました。
puts "\u304c"
puts "String#encode('Shift_JIS') => #{"\u304c".encode('Shift_JIS').inspect}"
puts "codepoints => #{"\u304c".codepoints}"
puts "NFKC normalized codepoints => #{"\u304c".unicode_normalize(:nfkc).codepoints}"
puts "Encode to SJIS with NFKC => #{"\u304c".unicode_normalize(:nfkc).encode('Shift_JIS').inspect}"
puts "=" * 20
puts "\u304b\u3099"
puts "String#encode('Shift_JIS', undef: :replace) => #{"\u304b\u3099".encode('Shift_JIS', undef: :replace).inspect}"
puts "codepoints => #{"\u304b\u3099".codepoints.inspect}"
puts "NFKC normalized codepoints => #{"\u304b\u3099".unicode_normalize(:nfkc).codepoints}"
puts "Encode to SJIS with NFKC => #{"\u304b\u3099".unicode_normalize(:nfkc).encode('Shift_JIS').inspect}"
puts "=" * 20
puts "\u0063\u006d"
puts "String#encode('Shift_JIS') => #{"\u0063\u006d".encode('Shift_JIS').inspect}"
puts "codepoints => #{"\u0063\u006d".codepoints}"
puts "NFKC normalized codepoints => #{"\u0063\u006d".unicode_normalize(:nfkc).codepoints}"
puts "=" * 20
puts "\u339d"
puts "String#encode('Shift_JIS', undef: :replace) => #{"\u339d".encode('Shift_JIS', undef: :replace).inspect}"
puts "codepoints => #{"\u339d".codepoints}"
puts "NFKC normalized codepoints => #{"\u339d".unicode_normalize(:nfkc).codepoints}"
$ ruby script.rb
が
String#encode('Shift_JIS') => "\x{82AA}"
codepoints => [12364]
NFKC normalized codepoints => [12364]
Encode to SJIS with NFKC => "\x{82AA}"
====================
が
String#encode('Shift_JIS', undef: :replace) => "\x{82A9}?"
codepoints => [12363, 12441]
NFKC normalized codepoints => [12364]
Encode to SJIS with NFKC => "\x{82AA}"
====================
cm
String#encode('Shift_JIS') => "cm"
codepoints => [99, 109]
NFKC normalized codepoints => [99, 109]
====================
㎝
String#encode('Shift_JIS', undef: :replace) => "?"
codepoints => [13213]
NFKC normalized codepoints => [99, 109]
https://wandbox.org/permlink/CQaSM6ffOHc0zLu6
Rubyにおいては、Unicode正規化を行うには String#unicode_normalize によって行うことができます。その際にoptionとして正規化の形式を指定することができます。とても簡単ですね。
https://docs.ruby-lang.org/ja/latest/class/String.html#I_UNICODE_NORMALIZE
Python
import unicodedata
print('\u304c (U+304c)')
print('codepoints => ', end='')
for char in '\u304c'.strip():
print(hex(ord(char)) + ' ' , end='')
print()
print('NFKC normalized codepoints => ', end='')
for char in unicodedata.normalize('NFKC', '\u304c').strip():
print(hex(ord(char)) + ' ' , end='')
print()
print('=' * 20)
print('\u304b\u3099 (U+304b U+3099)')
print('codepoints => ', end='')
for char in '\u304b\u3099'.strip():
print(hex(ord(char)) + ' ' , end='')
print()
print('NFKC normalized codepoints => ', end='')
for char in unicodedata.normalize('NFKC', '\u304b\u3099').strip():
print(hex(ord(char)), end='')
print()
print('=' * 20)
print('\u0063\u006d (U+0063 U+006d)')
print('codepoints => ', end='')
for char in '\u0063\u006d'.strip():
print(hex(ord(char)) + ' ' , end='')
print()
print('NFKC normalized codepoints => ', end='')
for char in unicodedata.normalize('NFKC', '\u0063\u006d').strip():
print(hex(ord(char)) + ' ' , end='')
print()
print('=' * 20)
print('\u339d (U+339d)')
print('codepoints => ', end='')
for char in '\u339d'.strip():
print(hex(ord(char)) + ' ' , end='')
print()
print('NFKC normalized codepoints => ', end='')
for char in unicodedata.normalize('NFKC', '\u339d').strip():
print(hex(ord(char)) + ' ' , end='')
print()
https://wandbox.org/permlink/cMc7S5blWLZLLObD
Pythonにおいては、unicodedata モジュールをインポートすることによって使用できる unicodedata.normalize により、形式を指定して正規化を行うことができます。
unicodedata — Unicode データベース — Python 3.8.5 ドキュメント
Go
package main
import (
"fmt"
"strings"
"unicode/utf8"
"golang.org/x/text/unicode/norm"
)
func printCodepoints(str string) {
fmt.Print("codepoints => ")
for i, w := 0, 0; i < len(str); i += w {
runeValue, width := utf8.DecodeRuneInString(str[i:])
fmt.Printf("%U ", runeValue)
w = width
}
fmt.Print("\n")
}
func main() {
fmt.Println("\u304c (U+304c)")
printCodepoints("\u304c")
fmt.Print("NFKC normalized ")
printCodepoints(norm.NFKC.String("\u304c"))
fmt.Println(strings.Repeat("=", 20))
fmt.Println("\u304b\u3099 (U+204c u+3099)")
printCodepoints("\u304b\u3099")
fmt.Print("NFKC normalized ")
printCodepoints(norm.NFKC.String("\u304b\u3099"))
fmt.Println(strings.Repeat("=", 20))
fmt.Println("\u0063\u006d (U+0063 U+006d)")
printCodepoints("\u0063\u006d")
fmt.Print("NFKC normalized ")
printCodepoints(norm.NFKC.String("\u0063\u006d"))
fmt.Println(strings.Repeat("=", 20))
fmt.Println("\u339d (U+339d)")
printCodepoints("\u339d")
fmt.Print("NFKC normalized ")
printCodepoints(norm.NFKC.String("\u339d"))
}
https://play.golang.org/p/xG255G32mlJ
Goでは、norm packageを使用することで正規化を行うことができます。
- norm package · pkg.go.dev
- Strings, bytes, runes and characters in Go - The Go Blog
- Goでの文字列の正規化 (Text normalization in Go) | The Go Blog 日本語訳
JavaScript
// function from https://jsprimer.net/basic/string-unicode/#code-point-is-not-code-unit
function convertCodeUnits(str) {
const codeUnits = [];
for (let i = 0; i < str.length; i++) {
codeUnits.push(str.charCodeAt(i).toString(16));
}
return codeUnits;
}
console.log('\u304c (U+304c)')
console.log('codepoints => ' + convertCodeUnits('\u304c'))
console.log('NFKC normalized codepoints => ' + convertCodeUnits('\u304c'.normalize('NFKC')))
console.log('=' .repeat(20))
console.log('\u304b\u3099 (U+304b U+3099)')
console.log('codepoints => ' + convertCodeUnits('\u304b\u3099'))
console.log('NFKC normalized codepoints => ' + convertCodeUnits('\u304b\u3099'.normalize('NFKC')))
console.log('='.repeat(20))
console.log('\u0063\u006d (U+0063 U+006d)')
console.log('codepoints => ' + convertCodeUnits('\u0063\u006d'))
console.log('NFKC normalized codepoints => ' + convertCodeUnits('\u0063\u006d'.normalize('NFKC')))
console.log('='.repeat(20))
console.log('\u339d (U+339d)')
console.log('codepoints => ' + convertCodeUnits('\u339d'))
console.log('NFKC normalized codepoints => ' + convertCodeUnits('\u339d'.normalize('NFKC')))
console.log('='.repeat(20))
https://wandbox.org/permlink/JLQH8LasdQo9ewgS
JavaScriptでは、 String.prototype.normalize() によって正規化を行うことができます。
それでは他のツールはどうでしょうか。
nkf
nkfはNetwork Kanji Filterの略で、古くからある文字コード変換ツールです。
https://ja.osdn.net/projects/nkf/
Rubyはnkfを同梱しているので、手軽に試すことができます。今回は一度Shift_JISに変換してからUTF-8に戻すことで、正しく変換できているかを確認してみます。
require 'kconv' # kconvはnkfのラッパーです
puts "\u304c (U+304c)"
puts "Endoce to SJIS by nkf => #{"\u304c".tosjis.inspect}"
puts "=" * 20
puts "\u304b\u3099 (U+304b U+3099)"
puts "Endoce to SJIS to UTF-8 by nkf => #{"\u304b\u3099".tosjis.toutf8}"
puts "=" * 20
puts "\u0063\u006d (U+0063 U+006d)"
puts "Endoce to SJIS by nkf => #{"\u0063\u006d".tosjis.inspect}"
puts "=" * 20
puts "\u339d (U+339d)"
puts "Endoce to SJIS to UTF-8 by nkf => #{"\u339d".tosjis.toutf8}"
$ ruby script.rb
が (U+304c)
Endoce to SJIS by nkf => "\x{82AA}"
====================
が (U+304b U+3099)
Endoce to SJIS to UTF-8 by nkf => 縺九y
====================
cm (U+0063 U+006d)
Endoce to SJIS by nkf => "cm"
====================
㎝ (U+339d)
Endoce to SJIS to UTF-8 by nkf => ㎝
このように、「が」(U+304B U+3099) の変換に失敗していることがわかります。そもそもnkfはUnicodeにおける正規化形式を指定できるのでしょうか。
nkfは2006-03-27にリリースされた 2.0.6 以降 (正確には2.0.6-beta2以降) においてUnicodeの正規化に対応するようになりましたが、「UTF8-MACの範囲のみ」と明言されています。
ここでの UTF-8-MAC は、macOSがAPFS以前1に採用していた HFS+ というファイルシステムにおいて使用されている正規化形式の通称2で、一見NFD形式のようで互換性のない正規化3を行っています。
- Ruby: UTF-8-MAC(UTF-8-HFS) を UTF-8 (NFC) に変換する - Sarabande.jp
- macOS iconv(3) UTF-8-MAC エンコーディングの問題 - OSSTech Advent Calendar 2019 - ダメ出し Blog
nkfは入力においてのみUTF-8-MACを受け付けるようになっているようで、他の正規化形式に対応していません。
nkfにオプションから文字コードを指定した変換をして確かめてみましょう。
# nkf.rbとして保存
require 'nkf'
puts "\u304b\u3099 : U+304b U+3099"
puts "nkf --ic=UTF-8 --oc=Shift_JIS"
ga_to_sjis_from_utf8 = NKF.nkf('--ic=UTF-8 --oc=Shift_JIS', "\u304b\u3099")
puts ga_to_sjis_from_utf8.inspect
puts ga_to_sjis_from_utf8.encode('UTF-8')
puts "=" * 20
puts "nkf --ic=UTF-8-MAC --oc=Shift_JIS"
ga_to_sjis_from_utf8mac = NKF.nkf('--ic=UTF-8-MAC --oc=Shift_JIS', "\u304b\u3099")
puts ga_to_sjis_from_utf8mac.inspect
puts ga_to_sjis_from_utf8mac.encode('UTF-8')
puts "=" * 20
puts "\ufa19 (U+fa19)"
puts "NFD normalized => #{"\ufa19".unicode_normalize(:nfd).inspect}"
puts "NFKC normalized => #{"\ufa19".unicode_normalize(:nfkc).inspect}"
puts "nkf convert => #{NKF.nkf('--ic=UTF-8-MAC --oc=UTF-8', "\ufa19").inspect}"
$ ruby nkf.rb
が : U+304b U+3099
nkf --ic=UTF-8 --oc=Shift_JIS
"\x{82A9}"
か
====================
nkf --ic=UTF-8-MAC --oc=Shift_JIS
"\x{82AA}"
が
====================
神 (U+fa19)
NFD normalized => "\u795E"
NFKC normalized => "\u795E"
nkf convert => "\uFA19"
ところで、㎝ (U+339D)の変換にも失敗しそうな気がしますが、成功しています。これはどういうことなのでしょうか。
Shift_JISに含まれる文字列の集合はJIS X 0201とJIS X 0208です。このどちらにも1文字で"cm"となる字体は定義されていません。4ではこの「㎝」はどこからやってきたのでしょうか。
「㎝」はNEC特殊文字に含まれており、NECやIBMによるShift_JIS拡張が統合された文字コードであるWindows-31Jに含まれています。これをCP932と呼ぶこともあり5、CP932からUnicodeへの文字変換表には CP932における 0x8770 をUnicodeでの 0x339D に変換すると定義されています。
https://www.unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP932.TXT
Shift_JISの規定において、0x8770 は「保留域」となっています。6 このことからも、JISに規定されているShift_JISにはなく、それの拡張であるWindows-31Jに含まれている文字であることがわかります。7
また余談として、JIS X 0213にて規定されたShift_JISX0213における 0x8770 に「㎝」の字形が含まれています。8
これもnkfで確認することができ、CP932において拡張された文字を扱わないオプション --no-cp932ext を指定することで文字が消えていることが確かめられます。
require 'nkf'
puts "\u339d : U+339d"
cm_to_sjis_from_utf8 = NKF.nkf('--ic=UTF-8 --oc=Shift_JIS --no-cp932ext', "\u339d")
puts cm_to_sjis_from_utf8.inspect
puts cm_to_sjis_from_utf8.encode('UTF-8').inspect
puts "=" * 20
$ ruby nkf.rb
㎝ : U+339d
""
""
====================
nkfでは、事前にNFKC正規化を行ってからでないと正しくShift_JISに変換できないことがわかりました。
iconv
iconvは、以前はRubyの標準添付ライブラリでしたが、2.0で削除されました。
https://www.ruby-lang.org/ja/news/2013/02/24/ruby-2-0-0-p0-is-released/
現在でもgemとしてインストールできるようにはなっていますが、String#encode を使用することが推奨されているので、今回はコマンドラインの結果をみることにします。
# iconv.rbとして保存
require 'open3'
puts "\u304c (U+304c)"
puts "String#encode('Shift_JIS') => #{"\u304c".encode('Shift_JIS').inspect}"
Open3.popen2e('iconv --from-code=UTF-8 --to-code=SHIFT-JIS') do |stdin, stdout_e, _|
stdin.print "\u304c"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by iconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
puts "=" * 20
puts "\u304b\u3099 (U+304b U+3099)"
puts "String#encode('Shift_JIS', undef: :replace) => #{"\u304b\u3099".encode('Shift_JIS', undef: :replace).inspect}"
Open3.popen2e('iconv --from-code=UTF-8 --to-code=SHIFT-JIS') do |stdin, stdout_e, _|
stdin.print "\u304b\u3099"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by iconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
puts "=" * 20
puts "\u0063\u006d (U+0063 U+006d)"
puts "String#encode('Shift_JIS') => #{"\u0063\u006d".encode('Shift_JIS').inspect}"
Open3.popen2e('iconv --from-code=UTF-8 --to-code=SHIFT-JIS') do |stdin, stdout_e, _|
stdin.print "\u0063\u006d"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by iconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
puts "=" * 20
puts "\u339d (U+339d)"
puts "String#encode('Shift_JIS', undef: :replace) => #{"\u339d".encode('Shift_JIS', undef: :replace).inspect}"
Open3.popen2e('iconv --from-code=UTF-8 --to-code=SHIFT-JIS') do |stdin, stdout_e, _|
stdin.print "\u339d"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by iconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
Open3.popen2e('iconv --from-code=UTF-8 --to-code=SHIFTJISX0213') do |stdin, stdout_e, _|
stdin.print "\u339d"
stdin.close
result = stdout_e.read
puts "Convert to ShiftJISX0213 by iconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('CP932').encode('UTF-8')}"
end
$ bundle exec ruby iconv.rb
が (U+304c)
String#encode('Shift_JIS') => "\x{82AA}"
Convert to Shift_JIS by iconv => "\x82\xAA"
Re-convert to UTF-8 => が
====================
が (U+304b U+3099)
String#encode('Shift_JIS', undef: :replace) => "\x{82A9}?"
Convert to Shift_JIS by iconv => "\x82\xA9iconv: illegal input sequence at position 3\n"
Re-convert to UTF-8 => かiconv: illegal input sequence at position 3
====================
cm (U+0063 U+006d)
String#encode('Shift_JIS') => "cm"
Convert to Shift_JIS by iconv => "cm"
Re-convert to UTF-8 => cm
====================
㎝ (U+339d)
String#encode('Shift_JIS', undef: :replace) => "?"
Convert to Shift_JIS by iconv => "iconv: illegal input sequence at position 0\n"
Re-convert to UTF-8 => iconv: illegal input sequence at position 0
Convert to ShiftJISX0213 by iconv => "\x87p"
Re-convert to UTF-8 => ㎝
nkfと同様に「が」(U+304B U+3099) の変換に失敗している様子がわかります。「か」までの出力には成功していることから、濁点 U+3099 の変換に失敗していそうですね。
またnkfについての説明で触れた「㎝」 (U+339D) については、Shift_JISへの変換は失敗していますが、Shift_JISX0213への変換は成功していますね。
他に指定できそうなoptionもないので、iconvでも事前にNFKC正規化しておく必要がありそうです。
uconv
それでは、Rubyを使用せずコマンドラインから使用できる、Unicodeの正規化形式も扱うことのできるツールはないのでしょうか?
これを行うことのできる uconv というものがあります。これはUnicode Consortiumが保守しているInternational Components for Unicodeというコンポーネント(?)に含まれており、Debianにおいては icu-devtools というパッケージ名で入手できます。
https://packages.debian.org/buster/icu-devtools
uconvに対して -x nfkc というふうに正規化形式を指定する(正確には、適用したいTransliterationを指定する)ことによって、NFKC正規化がされた上で文字コードの変換ができます。
require 'open3'
puts "\u304c (U+304c)"
puts "String#encode('Shift_JIS') => #{"\u304c".encode('Shift_JIS').inspect}"
Open3.popen2e('uconv --from-code UTF-8 --to-code Shift_JIS -x nfkc') do |stdin, stdout_e, _|
stdin.print "\u304c"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by uconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
puts "=" * 20
puts "\u304b\u3099 (U+304b U+3099)"
puts "String#encode('Shift_JIS', undef: :replace) => #{"\u304b\u3099".encode('Shift_JIS', undef: :replace).inspect}"
Open3.popen2e('uconv --from-code UTF-8 --to-code Shift_JIS -x nfkc') do |stdin, stdout_e, _|
stdin.print "\u304b\u3099"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by uconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
puts "=" * 20
puts "\u0063\u006d (U+0063 U+006d)"
puts "String#encode('Shift_JIS') => #{"\u0063\u006d".encode('Shift_JIS').inspect}"
Open3.popen2e('uconv --from-code UTF-8 --to-code Shift_JIS -x nfkc') do |stdin, stdout_e, _|
stdin.print "\u0063\u006d"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by uconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8')}"
end
puts "=" * 20
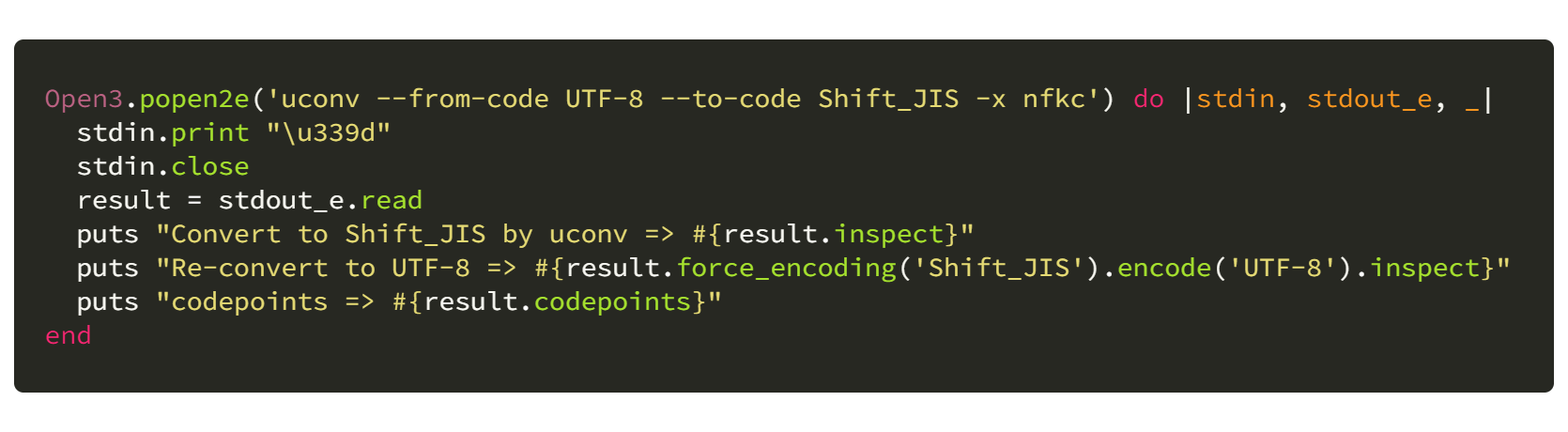
puts "\u339d (U+339d)"
puts "String#encode('Shift_JIS', undef: :replace) => #{"\u339d".encode('Shift_JIS', undef: :replace).inspect}"
Open3.popen2e('uconv --from-code UTF-8 --to-code Shift_JIS -x nfkc') do |stdin, stdout_e, _|
stdin.print "\u339d"
stdin.close
result = stdout_e.read
puts "Convert to Shift_JIS by uconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('Shift_JIS').encode('UTF-8').inspect}"
puts "codepoints => #{result.codepoints}"
end
Open3.popen2e('uconv --from-code UTF-8 --to-code cp932') do |stdin, stdout_e, _|
stdin.print "\u339d"
stdin.close
result = stdout_e.read
puts "Convert to CP932 by uconv => #{result.inspect}"
puts "Re-convert to UTF-8 => #{result.force_encoding('CP932').encode('UTF-8')}"
puts "codepoints => #{result.codepoints}"
end
$ bundle exec ruby uconv.rb
が (U+304c)
String#encode('Shift_JIS') => "\x{82AA}"
Convert to Shift_JIS by uconv => "\x82\xAA"
Re-convert to UTF-8 => が
====================
が (U+304b U+3099)
String#encode('Shift_JIS', undef: :replace) => "\x{82A9}?"
Convert to Shift_JIS by uconv => "\x82\xAA"
Re-convert to UTF-8 => が
====================
cm (U+0063 U+006d)
String#encode('Shift_JIS') => "cm"
Convert to Shift_JIS by uconv => "cm"
Re-convert to UTF-8 => cm
====================
㎝ (U+339d)
String#encode('Shift_JIS', undef: :replace) => "?"
Convert to Shift_JIS by uconv => "cm"
Re-convert to UTF-8 => "cm"
codepoints => [99, 109]
Convert to CP932 by uconv => "\x87p"
Re-convert to UTF-8 => ㎝
codepoints => [34672]
このように、NFKC正規化を行ったうえで、正しくShift_JISに変換できていることが、またCP932を指定したときには正規化を行わなくても「㎝」 (U+339D)を1文字のまま相互に変換できていることがわかります。
ちなみにTransliterationを活用するとこのようにひらがなをローマ字に変換するという面白いこともできます。
$ echo おはようございます | uconv -x '::hiragana-latin;'
ohayougozaimasu
余談 Unicodeにおける正規化形式について
元記事や現在において指定できる正規化形式、NFC、NFD、NFKC、NFKDの4つは、それぞれの名前が規格に登場するのはUnicode 3.0.1からであり、そのリリースは 2000-08-31 です。
https://web.archive.org/web/20050211134342/http://www.unicode.org/unicode/reports/tr15/tr15-19.html
それ以前のリリースにおいては、正規化形式について触れられている記述がなく、前述のUnicode Standard Annex #15から参照できる"Previous Version" においても、 “It is a stable document and may be used as reference material” などの記述が存在しないことから、正規化形式というものが存在するのはUnicode 3.0.1 以降ということになります。
https://web.archive.org/web/20050207015030/http://www.unicode.org/unicode/reports/tr15/tr15-18.html
このあたりの話は、技術評論社から出版されている[改訂新版]プログラマのための文字コード技術入門 の Appendix 4「Unicodeの諸問題」にて詳細に説明されています。この本はとても面白いのでぜひ読んでみてください。
まとめ
あるUnicode文字列に対してNFKCなどの正規化を適用したい場合、Rubyでは String#unicode_normalize にオプションとして、コマンドラインでは uconv を使用することで目的を達成できます。文字コード変換で良く知られるnkfやiconvでは適切に正規化が行われていない文字列を変換することができません。
-
ではAPFSではどうなのかというと、規格書には
j_drec_hashed_jey_t構造体に格納されるname_len_and_hashを計算するときにNFD正規化を行うとこが記載されていますが、ファイル名そのものの正規化についての記述は見付かりませんでした。 https://developer.apple.com/support/downloads/Apple-File-System-Reference.pdf 正規化が行われず、与えられたバイト列をそのまま保持するようになっているのか、同じ名前に見えるファイルを複数作成することができるという記事もあります。 https://eclecticlight.co/2017/04/06/apfs-is-currently-unusable-with-most-non-english-languages/ ↩ -
軽く目を通しましたが、Apple側でこの正規化形式に名前をつけたりはしていないようです。 https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/BPFileSystem/BPFileSystem.html#//apple_ref/doc/uid/10000185-SW1 ただし、Appleの配布しているiconvのencodingには
UTF-8-MACを指定できるので、ほぼ公式だとしていいでしょう。 ↩ -
https://developer.apple.com/library/archive/qa/qa1173/_index.html より ↩
-
JIS X 0208-1997 附属書3 表1より https://www.jisc.go.jp/pdfb6/PDFView/ShowPDF/5gMAAIAz9AGm_33fhhRp ↩
-
「呼ぶこともあり」というのは、当初定められたCP932をいくつかのベンダが独自拡張したあと、それをMicrosoftが統合したWindows-31JのこともCP932と呼ぶからです。現代においてはCP932 = Windows31J としていいと思いますが。 ↩
-
JIS X 0208-1997 附属書1より https://www.jisc.go.jp/pdfa8/PDFView/ShowPDF/7gIAAKR6fwk8ZKtaZttC ↩
-
MSDNに記載されていたCP932の文字一覧より https://web.archive.org/web/20180405180457/https://msdn.microsoft.com/en-us/library/cc194892.aspx ↩
-
JIS X 0213-2000 附属書4 表23より https://www.jisc.go.jp/pdfa5/PDFView/ShowPDF/5AIAAHLePslwm6mc6z4g ↩